100% Seguro | Sem Anúncios |
100% Seguro | Sem Anúncios |Como podemos extrair imagens dum PDF com o Python? Este guia acompanha você no processo de extração de imagens dum PDF com o Python.
Alguns arquivos PDF têm imagens que gostaríamos de extrair e usar como materiais de recurso ou para incluir noutros trabalhos ou projetos. Num caso assim, você terá que buscar uma forma de extrair as imagens e as salvar no seu formato de eleição. Continue lendo este artigo para aprender como o Python pode extrair imagens de arquivos PDF eficazmente.
Como Extrair Imagens dum PDF com o Python
A linguagem de programação Python vem a calhar quanto você necessita extrair imagens de arquivos PDF. As imagens podem estar em qualquer formato dependendo da saída que você escreve no código. Para além disso, o Python tem várias bibliotecas que lhe podem permitir extrair imagens de arquivos PDF. Estes são os passos para extrair Imagens dum PDF com o Python.
- Passo 1. Neste caso, você vai precisar de ter as bibliotecas PyPDF2 e Pillow instaladas no seu computador.
- Passo 2. De seguida, abra a linguagem de programação de distribuição que você usa, como Anaconda, e abra o Jupyter Lab.
- Passo 3. Depois disso, escreva o código a seguir conforme foi postado no Stack Overflow.

Alternativamente, você pode usar o módulo PyMuPDF que irá extrair as imagens do PDF usando o Python em formato PNG. Este é o código para isso:

Como Extrair Imagens dum PDF sem o Python
Trabalhar com o Python para extrair imagens dum PDF exige que você perceba de linguagem de programação Python, para poder compreender as linhas de código ou scripts facultados. Caso contrário, o método acima não lhe será útil. No entanto, se você desejar tirar imagens de arquivos PDF sem o Python, você precisa usar um extrator de imagens de PDF como o PDFelement. Este é um software de PDF que é compatível com os sistemas operacionais Windows e Mac. Este software permite que você abra arquivos PDF, visualize PDFs e extraia imagens de arquivos PDF. Para além disso, você pode extrair imagens dos arquivos PDF e salvá-las em formatos de imagem diferentes como PNG, JPEG, GIF, BMP e TIFF.
- A sua interface de usuário tem um ótimo design e você pode navegar, rolar pelas páginas e localizar menus e ícones.
- Cria arquivos com capturas de tela, imagens, arquivos PDF existentes e outros formatos de arquivo.
- O seu editor incorporado permite que você altere textos, imagens, objetos e links dum PDF. Você também pode adicionar marcas d’água, alterar o plano de fundo, adicionar numeração de bates e também cabeçalhos e rodapés.
- Ele tem tecnologia de OCR integrada que escaneia um ou múltiplos arquivos baseados em imagem e os torna editáveis.
- Ele converte arquivos PDF em formatos como HTML, PowerPoint, Excel, Texto Simples, EPUB, Word e Imagens.
- Anota PDFs usando caixas de texto, comentários, carimbos e desenhos.
- Permite que você crie formulários em PDF, preencha formulários em PDF e extraia dados de formulários em PDF.
- Protege arquivos PDF com senhas, permissões e assinaturas digitais. Você também pode editar as assinaturas ou eliminá-las permanentemente.
Este é um guia passo a passo para extrair imagens dum PDF usando o PDFelement.
Passo 1. Entre no Modo "Editar"
Comece abrindo o aplicativo no seu computador e clique em "Abrir Arquivo" para carregar o seu arquivo PDF. Assim que você abrir o arquivo PDF com o programa, ative o modo de edição clicando no menu "Editar", e depois clicando no ícone "Editar".
Passo 2. Extraia as Imagens do PDF sem o Python
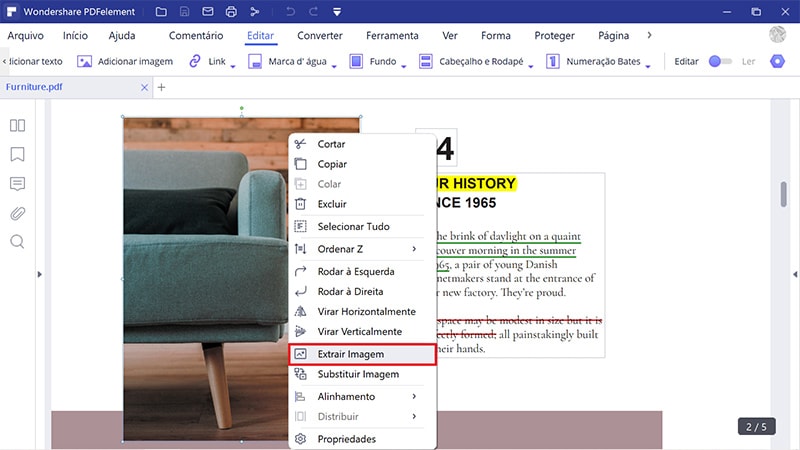
Em seguida, vá até à imagem que você deseja extrair sem o código Python e clique com o botão direito nela. Você verá que surgirá uma lista de opções no menu suspenso. Nesse menu, clique na opção "Extrair Imagem".
Passo 3. Salve a Imagem Extraída
Depois disso, irá aparecer uma janela de salvamento. Clique em "Salvar como Tipo" para selecionar o formato de saída da imagem como .png, .jpeg, .bmp, .gif ou .tiff. Na opção "Nome do arquivo ", você pode atribuir um nome à sua imagem e depois clicar em "Salvar". Ao fazer isso, você terá extraído as imagens do PDF sem o Python.