A obtenção de dados a partir de arquivos PDF é uma necessidade frequente em diversos setores, como o financeiro, o médico e o acadêmico. Com o crescimento do uso de PDFs para compartilhamento de informações, a demanda por soluções em Python para extração de dados tem aumentado significativamente. Realizar esse processo manualmente pode ser moroso e suscetível a falhas, comprometendo a precisão e a eficiência na manipulação das informações.
Neste texto
- Por que extrair dados de PDFs usando Python?
- Bibliotecas principais para extração de dados PDF em Python
- PDFelement: Simplifique todo o processo de extração de dados em PDF
- Benefícios do PDFelement em comparação com scripts Python manuais
- Como o PDFelement funciona perfeitamente com Python
- Guia passo a passo para extrair dados de PDFs usando Python e PDFelement
- Benefícios de combinar PDFelement com Python
Python se consolidou como uma ferramenta altamente eficaz para extrair conteúdo de arquivos PDF, tornando-se uma escolha popular entre profissionais da área. Graças a sua ampla gama de bibliotecas e uma sintaxe intuitiva, o Python facilita a obtenção e o processamento de dados contidos em documentos PDF. Neste artigo, exploraremos como o Python, aliado a soluções como o PDFelement, pode agilizar e aprimorar o processo de extração de informações de PDFs.
Por que extrair dados de PDFs usando Python?
O Python dispõe de uma vasta gama de recursos para lidar com PDFs, impulsionado por um ecossistema robusto de bibliotecas especializadas na extração de informações desses arquivos. Essas bibliotecas oferecem uma variedade de funcionalidades para atender a diferentes demandas no processo de extração de dados. Algumas bibliotecas notáveis incluem:
PyPDF2
Uma dessas ferramentas possibilita a obtenção de texto simples e a manipulação de PDFs, sendo uma excelente opção inicial para quem deseja extrair conteúdo sem lidar com formatação avançada.
PyMuPDF (Fitz)
Este programa extrai texto e anotações de forma eficaz. Com funcionalidades mais sofisticadas do que o PyPDF2, essa biblioteca se destaca na extração de informações estruturadas, tornando-se ideal para documentos que combinam texto com imagens ou anotações.
PDFMiner
Outra opção avançada permite extrair texto mantendo a estrutura original do documento, o que a torna especialmente útil para arquivos com layouts complexos. Os usuários podem acessar detalhes precisos sobre a posição e formatação do texto, o que é fundamental ao lidar com documentos estruturados.
Bibliotecas principais para extração de dados PDF em Python
PyPDF2
O PyPDF2 é uma das bibliotecas mais populares, oferecendo recursos essenciais para leitura e manipulação de arquivos PDF. Essa funcionalidade é especialmente vantajosa para quem deseja extrair informações de PDFs utilizando Python.
O que ele pode fazer:
- Extrair texto: Com essa função, é possível recuperar o texto de páginas individuais de um documento PDF, facilitando o acesso ao conteúdo desejado.
- Mesclar ou dividir PDFs: Combine múltiplos arquivos PDF em um único documento ou divida um arquivo extenso em partes menores para facilitar o gerenciamento.
Exemplos de quando usar:
- Ideal para extração de texto em PDFs simples, sem formatação elaborada, como faturas e relatórios.
- Unir vários PDFs em um único arquivo é uma solução prática para manter documentos relacionados organizados.
PyMuPDF (Fitz)
O PyMuPDF, também chamado de Fitz, é uma biblioteca avançada voltada para a extração de texto e anotações de documentos PDF. Seus recursos robustos fazem dele a opção ideal para usuários que precisam realizar extrações de dados mais sofisticadas em arquivos PDF usando Python.
Capacidade:
- Extração de texto eficiente: Permite a extração de texto mantendo o layout original, garantindo que a formatação seja preservada na saída.
- Acesso a imagens e mídia: Oferece a possibilidade de extrair imagens e outros elementos multimídia incorporados ao PDF, sendo ideal para arquivos com conteúdo visualmente rico.
Casos de uso ideais:
- Essencial para obter informações detalhadas junto com imagens ou anotações, como em artigos acadêmicos e materiais de marketing.
- Ideal para a extração de conteúdo em PDFs visualmente complexos, onde a manutenção da estrutura original é fundamental.
PDFMiner
O PDFMiner é uma biblioteca avançada desenvolvida especificamente para capturar informações detalhadas de PDFs, incluindo a organização do texto e seu layout. Recomendado para usuários que precisam de um alto nível de controle sobre a extração de dados de documentos PDF.
Recursos:
- Preservação de layout: Possui a capacidade de recuperar texto juntamente com a estrutura do documento, tornando-se uma excelente escolha para arquivos onde a disposição dos elementos é essencial.
- Análise avançada de texto: Disponibiliza ferramentas para a análise do layout de documentos, essencial para casos onde a preservação da formatação é fundamental.
Quando usar:
- Permite um controle detalhado sobre a extração de texto com base na sua posição no documento, sendo ideal para contratos legais e manuais técnicos.
- Facilita a análise do layout de documentos para garantir que os dados extraídos mantenham a estrutura original desejada.
Pandas para dados tabulares
A integração do Pandas com outras bibliotecas é extremamente útil para a extração de tabelas estruturadas de arquivos PDF. O Pandas possibilita a organização e análise eficiente dos dados extraídos, tornando-se uma ferramenta indispensável no processamento de PDFs com Python.
Benefícios:
- Manipulação de dados: Permite a manipulação de grandes volumes de dados extraídos de PDFs, otimizando processos de análise e geração de relatórios.
- Análise complexa: Realize análises detalhadas em dados estruturados com facilidade, aproveitando os robustos recursos de manipulação de informações do Pandas.
Utilizando bibliotecas como PyPDF2, PyMuPDF (Fitz), PDFMiner e Pandas, os usuários podem extrair dados de PDFs com Python de forma eficiente e personalizada para suas necessidades. Seja para capturar texto simples ou tabelas complexas, o ecossistema robusto do Python oferece todas as ferramentas essenciais para a extração eficiente de informações de PDFs.
PDFelement: Simplifique todo o processo de extração de dados em PDF
O PDFelement é uma solução completa para edição de PDFs, equipada com diversos recursos que facilitam o gerenciamento de documentos. Com ferramentas intuitivas, ele permite criar, editar, converter e extrair dados de PDFs de maneira prática e sem complicações.
Benefícios do PDFelement em comparação com scripts Python manuais
Comparado aos métodos tradicionais de extração via scripts manuais, o PDFelement oferece vantagens significativas em termos de facilidade e eficiência.
- Interface amigável: Sua interface amigável garante uma experiência acessível, mesmo para usuários sem conhecimento em programação. Essa facilidade de uso faz do PDFelement uma excelente opção para indivíduos ou equipes que precisam extrair dados de PDFs sem depender de habilidades técnicas avançadas.
- Tecnologia OCR: Conta com tecnologia de reconhecimento óptico de caracteres (OCR), permitindo a extração eficiente de texto a partir de PDFs digitalizados. Esse recurso é especialmente útil para lidar com documentos físicos convertidos em formato digital.
- Opções de exportação: Os usuários podem exportar os dados extraídos para formatos estruturados, como Excel, CSV ou Word, facilitando a manipulação posterior. As bibliotecas Python podem processar esses formatos rapidamente, garantindo uma integração fluida com fluxos de trabalho já estabelecidos.
Como o PDFelement funciona perfeitamente com Python
Com a interface intuitiva do PDFelement, é possível extrair dados facilmente e, em seguida, utilizar scripts Python para análise aprofundada. Essa abordagem combina o melhor dos dois mundos: o PDFelement simplifica a extração, enquanto o Python oferece recursos avançados para manipulação e análise dos dados extraídos.
Guia passo a passo para extrair dados de PDFs usando Python e PDFelement
Usando Python
Para começar a extrair informações de PDFs com Python, o primeiro passo é instalar as bibliotecas necessárias.
bash
pip install pypdf2 pymupdf pdfminer.six pandas
Exemplo de código simples para extrair dados de texto ou tabela
Aqui está um exemplo básico demonstrando como extrair texto usando PyPDF2:
python
from PyPDF2 import PdfReader
# Carregar o arquivo PDF
reader = PdfReader('example.pdf')
# Extrair texto de cada página
for page in reader.pages:
print(page.extract_text())
Limitações da extração somente Python
Embora as bibliotecas Python para extração de dados em PDF ofereçam grande flexibilidade, elas apresentam algumas limitações importantes.
- Problemas com documentos digitalizados: Ferramentas padrão podem não ser eficazes na manipulação de documentos digitalizados sem o suporte de OCR. Essa limitação representa um desafio significativo ao extrair informações de PDFs no Python, especialmente quando os arquivos são compostos majoritariamente por imagens.
- Perda de estrutura de dados: Se a extração de tabelas não for configurada corretamente, há risco de perda de formatação e estrutura dos dados. Isso pode dificultar análises futuras, principalmente quando a preservação do layout original é essencial. Muitos usuários enfrentam dificuldades ao extrair tabelas complexas de PDFs usando Python, pois essas estruturas exigem formatação precisa.
Usando PDFelement para extrair dados
Para extrair dados de PDF de forma eficaz usando PDFelement:
Passo
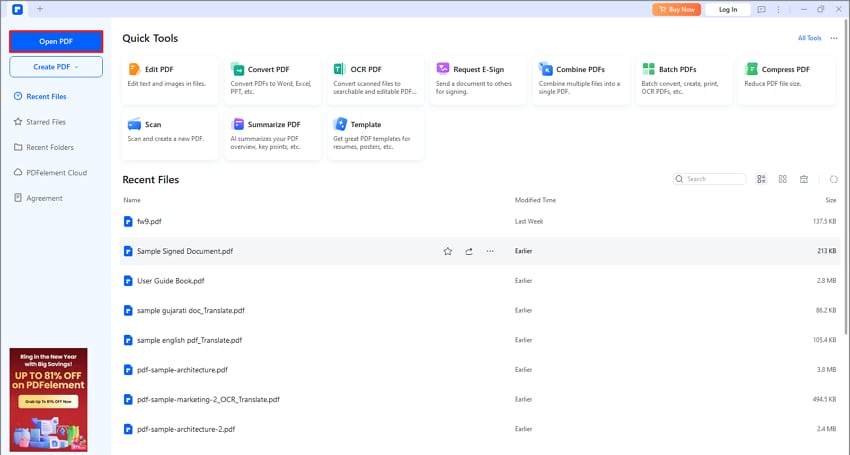
Abra o PDFelement e carregue seu documento PDF.


 Avaliação G2: 4,5/5 |
Avaliação G2: 4,5/5 | 100% Seguro
100% Seguro
Passo 2
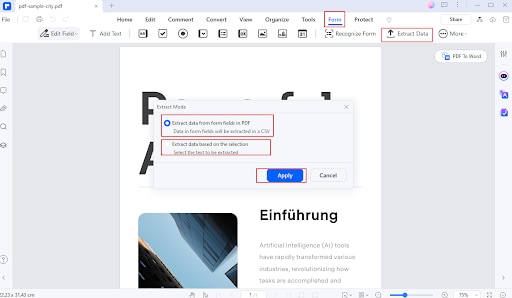
Navegue até a guia Formulário e selecione Extrair Dados.
Passo 3
Escolha as opções de extração desejadas (por exemplo, campos de formulário ou tabelas).
Benefícios de combinar PDFelement com Python
A integração do PDFelement com Python proporciona uma solução eficiente para quem deseja aprimorar o processo de extração de dados de PDFs, combinando facilidade de uso com recursos avançados.
- Aumento de eficiência: A integração da interface intuitiva do PDFelement com a flexibilidade do Python melhora a produtividade, permitindo que os usuários foquem na análise de dados em vez de se preocupar com a extração. Essa combinação é especialmente vantajosa para quem precisa extrair dados de PDFs com frequência utilizando Python.
- Precisão aprimorada: O PDFelement oferece suporte avançado a OCR, garantindo a extração precisa de textos em PDFs digitalizados, uma tarefa desafiadora para bibliotecas padrão. Esse recurso é essencial para evitar a perda de informações importantes durante o processo de extração.
- Economia de tempo: Tarefas repetitivas podem ser automatizadas de forma eficiente ao aproveitar o melhor das duas ferramentas. Um fluxo de trabalho otimizado pode envolver o uso do PDFelement para a extração inicial, seguido da aplicação de scripts Python para análises detalhadas ou geração de relatórios. Essa abordagem permite que empresas tornem seus processos mais ágeis, aumentando a eficiência na gestão de documentos em PDF.
Essa combinação é ideal para empresas que precisam lidar com grandes volumes de documentos PDF e conjuntos de dados complexos, onde precisão e eficiência são essenciais.
Avaliação G2: 4,5/5 |100% Seguro
Considerações Finais
Existem diversas opções disponíveis para extrair dados de PDFs com Python, incluindo bibliotecas como PyPDF2, PyMuPDF e PDFMiner. O PDFelement se destaca por agilizar a extração de dados, oferecendo uma interface intuitiva e funcionalidades avançadas que tornam o gerenciamento de documentos PDF mais eficiente. Além disso, o DocuSign disponibiliza um método prático para recusar assinaturas eletrônicas, que pode ser integrado ao fluxo de trabalho para otimizar ainda mais o manuseio de documentos em PDF.