Imagine trabalhar com centenas de páginas digitalizadas ou PDFs baseados em imagens e perceber que você não consegue copiar ou pesquisar nenhum texto dentro deles. É frustrante quando você só precisa extrair informações rapidamente ou construir um fluxo de trabalho automatizado. O DeepSeek muda isso ao transformar documentos digitalizados em texto legível por máquina usando sua avançada tecnologia de reconhecimento óptico de caracteres.
Seja para processar PDFs extensos, conectar via a API DeepSeek OCR ou explorar seus recursos no GitHub, este guia irá te orientar em tudo. Você também descobrirá uma alternativa OCR mais simples, sem código, para limpeza instantânea de PDF e extração de texto multilíngue.
Neste artigo
- Resposta rápida
- O que é DeepSeek OCR?
- DeepSeek OCR API — Como utilizar
- DeepSeek OCR no GitHub — Clonar e executar localmente
- Usando DeepSeek OCR para PDF
- Ollama + DeepSeek OCR (abordagem local)
- Um caminho mais rápido para equipes do dia a dia: PDFelement (OCR e limpeza de PDF sem código)
- DeepSeek OCR vs PDFelement vs OCR clássico — quando usar cada um
- Guias passo a passo (prontos para copiar)
- Considerações conhecidas (precisão, segurança, disponibilidade)
Parte 1. Resposta rápida
DeepSeek-OCR é um software open-source que usa "compressão ótica" para processar grandes documentos com contexto ultralongo. É ideal para desenvolvedores que precisam de extração em larga escala e está disponível no GitHub com documentação completa da API online. Para a maioria das equipes que precisam de OCR multilíngue com uma interface simples, os recursos de OCR e Otimização de Scanner do PDFelement são mais práticos. Escolha DeepSeek para eficiência de tokens e PDFelement para extração de texto e limpeza de PDFs no dia a dia com ferramentas amigáveis ao usuário.
Parte 2. O que é DeepSeek OCR?
Este sistema transforma documentos em tokens visuais compactos e permite processamento ultraeficiente de contexto longo para IA. Ele preserva a estrutura de layout complexa, reduz custos de tokens e fornece saída pronta para análise. Para ajudar modelos de linguagem a processar documentos longos em uma só etapa, ele comprime páginas em uma apresentação visual. Suporta documentos em vários idiomas e formatos mistos em fluxos de trabalho de pesquisa, empresariais e de desenvolvedores. Veja algumas das principais capacidades e vantagens desta ferramenta.

- Motor de Compressão Ótica: Converte páginas em tokens visuais compactos para que modelos de linguagem processem contextos muito mais longos.
- Redução de Tokens 10×: Reduz a quantidade de tokens em cerca de dez vezes enquanto mantém reconhecimento forte em layouts diversos.
- Processamento de Alta Vazão: Entrega alta vazão em cargas de trabalho de múltiplas páginas utilizando estratégias otimizadas de segmentação, processamento em lote e cache.
- Modos/Dinâmicas de Resolução: Adapta resoluções para PDFs científicos, notas fiscais, tabelas, gráficos e arquivos ricos em diagramas.
- Saídas Estruturadas: Gera Markdown ou JSON estruturado para preservar tabelas, listas, gráficos e hierarquia geral do documento.
Você pode explorar o resumo completo da pesquisa e exemplos de código no oficial do DeepSeek repositório GitHub e artigos técnicos.


 Avaliação G2: 4,5/5 |
Avaliação G2: 4,5/5 | 100% Seguro
100% Seguro
Parte 3. DeepSeek OCR API — Como utilizar
A DeepSeek OCR API permite que desenvolvedores integrem processamento avançado de documentos em seus fluxos de trabalho. É facilmente acessível para desenvolvedores familiarizados com SDKs do OpenAI, sem exigir entendimento de um novo formato de API, graças à sua compatibilidade com OpenAI. Usuários podem enviar páginas digitalizadas, imagens ou PDFs e receber texto estruturado como resposta. Os resultados estão prontos para fluxos de trabalho de IA, bases de conhecimento ou pipelines de pesquisa.
Formato da API e estrutura da requisição
A API utiliza uma estrutura de requisição HTTP padrão compatível com SDKs no estilo OpenAI. Uma requisição típica inclui:
- URL do Endpoint: O endereço para onde enviar requisições para processar documentos, por exemplo,https://api.deepseek.com/v1/ocr.
- Cabeçalhos: Inclua seu token Bearer e detalhes de autenticação necessários para acesso.
- Arquivo de Entrada: Forneça uma imagem, página PDF ou uma URL pública para processamento OCR.
- Parâmetros Opcionais: Especifique idioma, modo de layout, resolução ou outras preferências para melhores resultados.
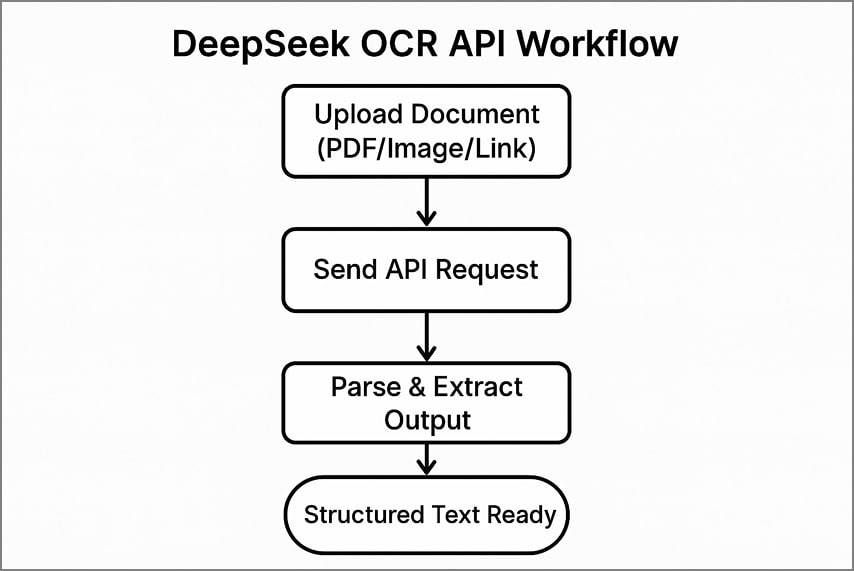
Fluxo típico de uso da API
Usar o DeepSeek OCR para API envolve 3 passos claros para processar documentos e extrair texto estruturado.
- Envie seu documento para a API, transmitindo um arquivo, página PDF ou link público.
- Realize a chamada à API com seus cabeçalhos de autenticação e opções de processamento escolhidas.
- Interprete o JSON ou texto retornado para extrair conteúdo reconhecido, detalhes de layout e tokens visuais com precisão.
Limites de taxa, disponibilidade e confiabilidade
Embora a API seja poderosa, os desenvolvedores devem estar atentos a algumas considerações operacionais:
- Disponibilidade do Serviço: A API apresentou oscilações ocasionais em tempo de funcionamento, então planeje para possíveis períodos de inatividade ou respostas mais lentas em produção.
- Limites de Taxa: Para grandes volumes de processamento, você pode atingir limites diários ou por minuto. Considere re-tentativas para manter a continuidade.
- Tratamento de Erros: Sempre confira as respostas para erros e trate exceções de forma adequada para evitar falhas de fluxo em produção.

Parte 4. DeepSeek OCR no GitHub — clonar e executar localmente
Vamos explorar como instalar o DeepSeek OCR do GitHub localmente configurando o ambiente Python após clonar o repositório.
Acessando o repositório
DeepSeek OCR está disponível como projeto open-source no GitHub, fornecendo aos desenvolvedores acesso total à sua arquitetura e scripts. O repositório inclui arquivos de configuração de ambiente e documentação para implantação ou customização. Distribuído sob uma licença permissiva, suporta uso tanto em pesquisa quanto produção. O projeto tem uma comunidade ativa com contribuições frequentes de correções de bugs e melhorias para implantação local.

Configuração local (passos)
Para instalar o DeepSeek OCR localmente, basta clonar o repositório e preparar seu ambiente Python:
"git clone https://github.com/deepseek-ai/DeepSeek-OCR
cd DeepSeek-OCR
python -m venv venv
source venv/bin/activate # Windows: venv\Scripts\activate
pip install -r requirements.txt"
A ferramenta é compatível com Python 3.9 ou superior. Os pesos do modelo podem ser baixados automaticamente no primeiro uso ou manualmente pelos links no README.
Requisitos para GPU e observações de performance
DeepSeek OCR pode rodar em CPU, embora uma GPU compatível com CUDA seja altamente recomendada para grandes volumes de OCR. Em comparações internas, é possível obter de 5 a 10 vezes mais velocidade em PDFs de múltiplas páginas ou layouts complexos usando aceleração via GPU. Para melhor desempenho, garanta que drivers NVIDIA, CUDA e versões do PyTorch estejam atualizados.
Realizando inferência em PDF
Após completar a configuração, teste um arquivo PDF de exemplo utilizando o seguinte comando:
"python infer.py --input sample.pdf --output output.json"
Cada página é renderizada como imagem e processada pelo pipeline de visão VL2 para detectar texto e reter o layout. A saída estruturada (JSON ou Markdown) pode ser integrada a fluxos de trabalho RAG ou LLMs locais baseados em Ollama.
Avaliação G2: 4,5/5 |100% Seguro
Parte 5. Usando DeepSeek OCR para PDF
Vamos ver como os desenvolvedores normalmente utilizam OCR em PDF para extrair dados textuais e de layout com precisão de documentos digitalizados ou digitais.
Métodos utilizados por desenvolvedores atualmente
Para PDFs, existem duas formas práticas de equipes utilizarem DeepSeek hoje, dependendo de qualidade, custo e latência.
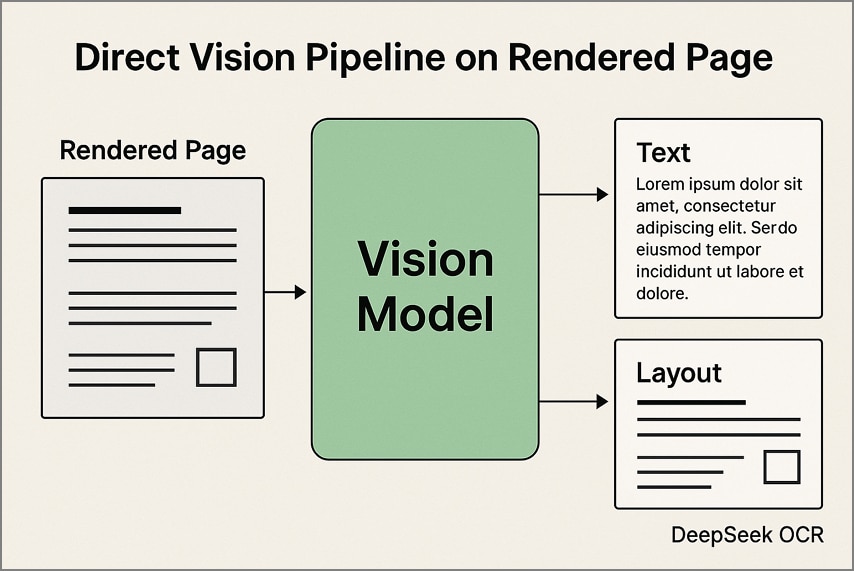
1. Pipeline de visão direta em páginas renderizadas
Nesta abordagem, cada página PDF é convertida em imagem em resolução fixa antes de ser processada pelo DeepSeek OCR. O modelo extrai texto e detalhes de layout direto das imagens, mantendo tabelas, colunas e diagramas em sua estrutura original. Este método é especialmente eficaz para documentos digitalizados e layouts visuais complexos.
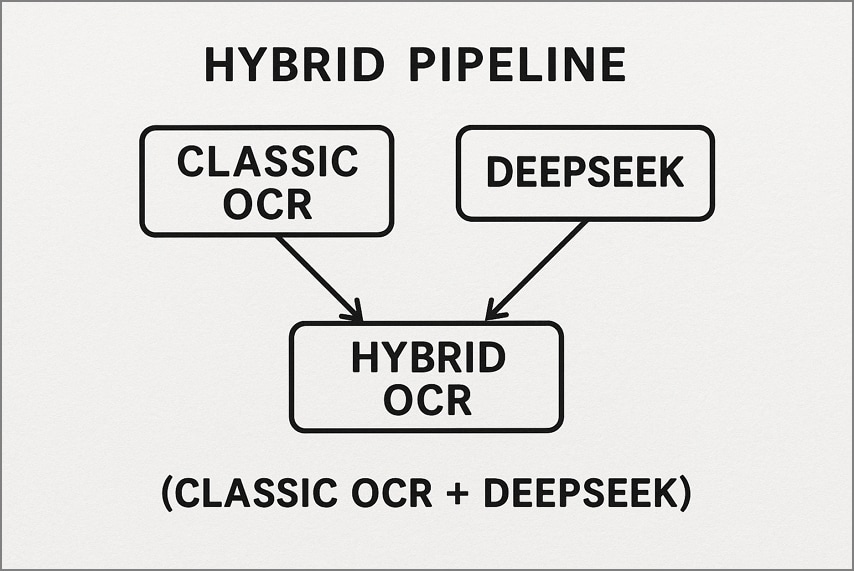
2. Pipeline Híbrido (OCR clássico + DeepSeek)
Aqui, uma ferramenta tradicional de OCR, como o Tesseract, processa primeiro as páginas simples e de alta qualidade para gerar texto rapidamente. Só as páginas mais complexas ou ruidosas são enviadas ao DeepSeek OCR para reconstrução de layout e compreensão semântica. Este fluxo reduz custos e latência sem perder precisão premium nos documentos difíceis.
Casos de Borda
Alguns documentos são mais difíceis de processar do que páginas de texto padrão, então é importante lidar com esses casos cuidadosamente para obter a melhor precisão no OCR.
- Revistas/Jornais Multicolunas: Garanta ordem correta das colunas agrupando linhas após OCR, prefira 300 DPI, processe por coluna em páginas densas.
- Selos/Carimbos/Marcas-d'água: Masque ou separe sobreposições antes do OCR para evitar falsos positivos e mesclas erradas, depois reinsira no final.
- Inclinação/Rotação: Alinhe as páginas primeiro, detecte orientação de maneira confiável e execute o OCR novamente nas páginas rotacionadas.
- Digitalizações de Baixo DPI: Faça upscale de 1,5 a 2 vezes e aplique nitidez, ou prefira digitalizar novamente com DPI maior.
- Tabelas e Formulários: Utilizar detector de tabelas ou alinhamento de cabeçalho para corrigir células divididas e validar totais e campos-chave.
- Fontes/Matemática/Código: Use tiles com resolução superior para equações, blocos de código e fontes muito pequenas, preservando espaçamento monoespaçado com cercas de código.
Por que o Pós-processamento é Importante
Pós-processamento é a limpeza simples após a extração do texto, garantindo que o resultado fique correto. Ele corrige colunas misturadas, tabelas quebradas, títulos confusos e selos lidos como palavras. Se encontrar algum erro, tente novamente aquela página com qualidade superior e confira totais, datas e IDs.
Parte 6. Ollama + DeepSeek OCR (abordagem local)
É um framework leve que executa modelos de linguagem grandes inteiramente em seu computador, com uma API local e CLI simples. Ollama DeepSeek OCR permite processar documentos digitalizados e PDFs de ponta a ponta na sua máquina, evitando dependências da nuvem e mantendo estrutura em saídas como Markdown ou JSON.
Integração Comunitária e Exemplos
Nesta seção, exploraremos projetos comunitários que combinam DeepSeek OCR com modelos Ollama para processamento, extração e análise local de documentos.
- Streamlit OCR Studio: Um dashboard Streamlit ingere PDFs e imagens e executa DeepSeek OCR para texto estruturado. O modelo responde localmente às perguntas do usuário sobre o conteúdo extraído.
- Extractor Markdown + Ollama QA: Ferramenta de imagem para Markdown usada para converter imagens de páginas em Markdown limpo para uso posterior. Um modelo de chat Ollama resume documentos e extrai campos-chave de PDFs e imagens digitalizadas.
- Analisador Local + API Ollama: Um serviço de pasta monitorada faz OCR de novos arquivos com DeepSeek à medida que chegam. Expõe um endpoint Ollama local para busca, perguntas e respostas, redação e automação de fluxo de trabalho.
Por que Orquestração Local Ajuda
Depois de rodar Ollama com DeepSeek OCR localmente, veja as principais vantagens deste setup.
- Mantenha documentos no dispositivo respeitando políticas rígidas de dados e reduzindo exposição a invasões em auditorias.
- Execute sem internet em laboratórios seguros ou redes isoladas, atendendo testes de conformidade.
- Evite atrasos de rede, controle lotes e cache localmente, estabilizando vazão em PDFs grandes.
Avaliação G2: 4,5/5 |100% Seguro
Parte 7. Um caminho mais rápido para equipes do dia a dia: PDFelement (OCR e limpeza de PDF sem código)
Muitos usuários sem experiência técnica costumam ter dificuldade para extrair texto de PDFs digitalizados ou documentos em imagem. Além do DeepSeek OCR, eles procuram ferramentas que ofereçam processamento OCR fácil, limpeza de documentos e extração rápida de texto, sem conhecimento técnico. É aí que o PDFelement entra, tornando a extração de PDFs simples com OCR sem código e ajudando equipes a converter documentos em formatos pesquisáveis em segundos.
Ao contrário de outras ferramentas, os usuários também podem sublinhar, adicionar marcas d'água, inserir fundos e conversar com a IA sobre seus PDFs. O PDFelement oferece até 20GB de armazenamento para salvar seus dados nesta ferramenta e compartilhá-los diretamente através das plataformas de mídia social. Além disso, para tornar a área de destino editável, ele fornece uma opção "área OCR" para selecionar uma parte específica do documento.
O guia definitivo para PDF OCR sem código no PDFelement
Depois de conhecer as melhores ferramentas de OCR de PDF para não codificadores, siga este fluxo de trabalho passo a passo para trabalhar rapidamente em PDFs como uma alternativa à API de OCR do DeepSeek:
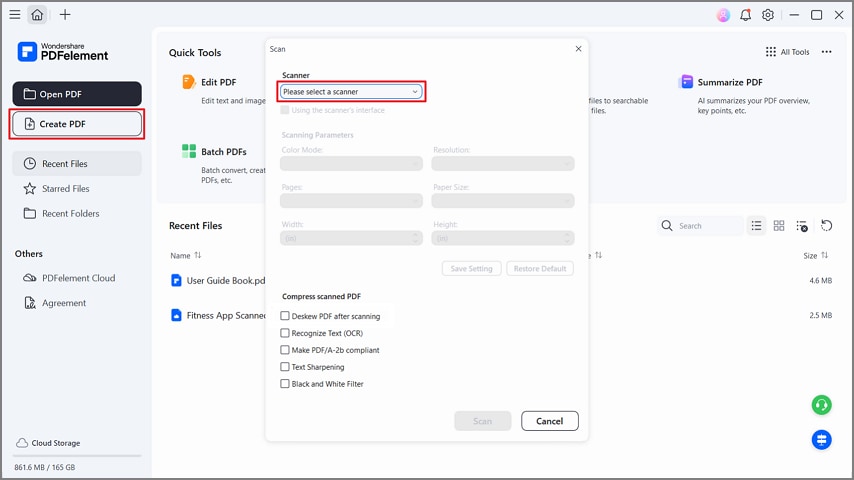
Passo 1Criar PDF a partir de um scanner
Depois de entrar na ferramenta, pressione o botão "Criar PDF" e selecione a opção "A partir do scanner" no menu suspenso. Em seguida, selecione o seu scanner e marque a opção "Corrigir PDF após digitalização". A ferramenta converte digitalizações em texto pesquisável ou editável com suporte de área de trabalho.
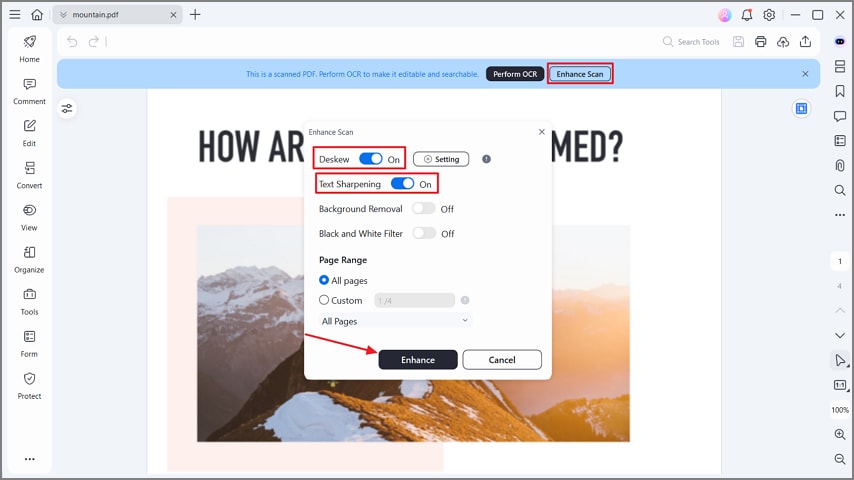
Passo 2Melhore o seu PDF
Depois de criar o PDF digitalizado, pressione o botão "Melhorar digitalização". Em seguida, alterne as opções "Desskew" e "Text Sharpen" e clique no botão "Aprimorar" na janela pop-up. Ele afiará o texto no PDF para melhorar a precisão do OCR em caso de digitalização ruim.
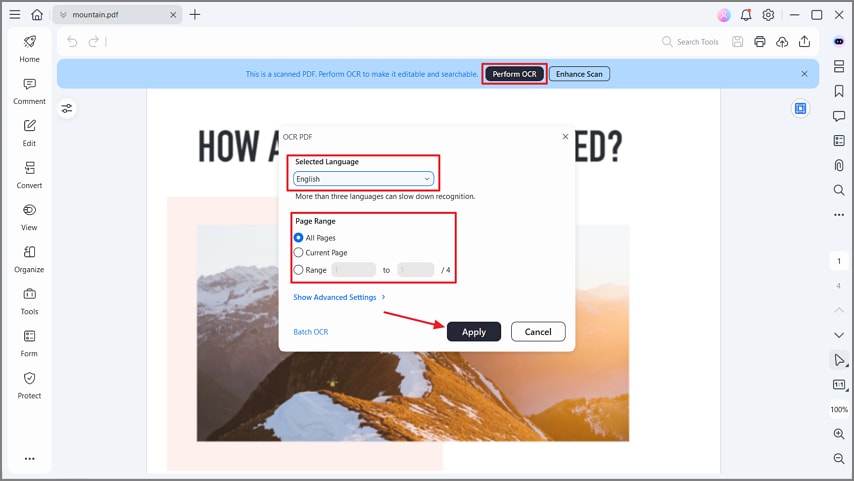
Passo 3Executar OCR de texto
Agora, clique no botão "Executar OCR" e selecione o idioma correto. Em seguida, selecione um "intervalo de página" específico e pressione o botão "Aplicar" para iniciar o processo de OCR. Isso extrairá o texto do seu PDF, tornando-o pesquisável e editável para visualização ou exportação.
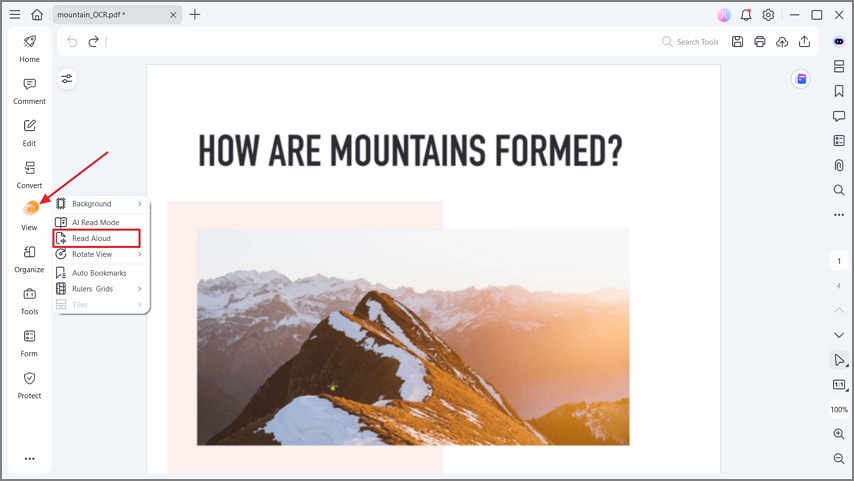
Passo 4Leia o PDF em voz alta
Quando o OCR estiver concluído, clique na opção "Ver" no menu esquerdo e pressione a opção "Leia em voz alta" para ouvir seu texto PDF. Você pode parar e pausar a ouvir a qualquer momento. Esse recurso permite que você revise seus PDFs para encontrar quaisquer erros.
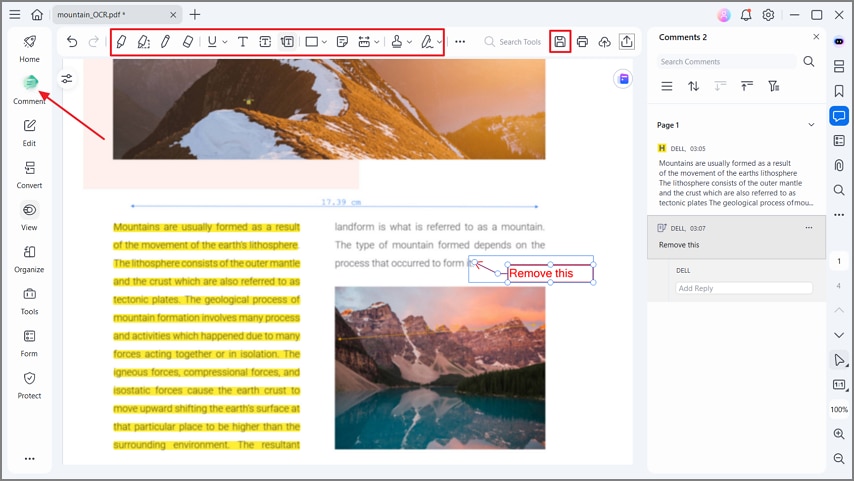
Passo 5Anotar e exportar PDF
Clique no botão Comentários e use as ferramentas da barra de ferramentas para destacar o texto e adicionar comentários ao PDF. Finalmente, pressione o botão "Salvar" para exportar o arquivo PDF. O recurso de anotação também ajuda a adicionar carimbos, desenhar formas, anexar adesivos e sublinhar ou sublinhar texto para uma melhor revisão do documento.
Avaliação G2: 4,5/5 |100% Seguro
Parte 8. DeepSeek OCR vs PDFelement vs Classic OCR – quando e o que usar
Depois de explorar as melhores alternativas de OCR do DeepSeek, vamos ver quais ferramentas são melhores para diferentes casos de uso e fluxos de trabalho de documentação.
DeepSeek OCR
Ideal para pilotos de desenvolvedores que precisam de inferência de contexto longo, RAG eficiente em tokens e saída Markdown ou JSON consciente de layout. Espere o trabalho de configuração e operação, incluindo redimensionamento de GPU/VRAM, seleção de lote ou tiles e ajustes ocasionais de casos de borda.
Wondershare PDFelement
Uma opção confiável para o trabalho diário de documentos que requer OCR multilíngue, digitalização visualmente aprimorada, anotação e revisão. A exportação com um clique para Word ou Excel simplifica a transferência e as equipes evitam a codificação ou o gerenciamento de GPU.
Biblioteca OCR clássica
Funciona melhor em alta taxa de transferência quando o layout é simples e consistente em todos os lotes. Adicione regras leves ou entregas de LLM direcionadas apenas em páginas difíceis para injetar semântica sem pagar em todos os lugares. Confira a tabela de comparação abaixo para ver como cada ferramenta se adapta aos diferentes fluxos de trabalho e necessidades do usuário.
| Ferramentas | Focus | configurar | Contexto longo | Limpeza | Multilinguismo | Mais adequado para |
| DeepSeek OCR | Desenvolvedor Workflow | Tecnologia | Médio | Limitado/Script | Médio | Desenvolvedores, Prototipagem, Pesquisa, Pipeline RAG |
| PDFelement | Edição e revisão de documentos | Sem código | Alto | Ferramentas GUI completas | Alto | Equipe de negócios, Operações, Conformidade, Arquivamento |
| OCR clássico | Processamento em lote, documentação simples | Tecnologia | Médio | Baseado em script | Médio | Trabalho em lote, back-end, layout simples |
Parte 9. Playbook passo a passo (copiável)
Agora que você entende como cada ferramenta se encaixa em diferentes fluxos de trabalho, vamos dar uma olhada no guia de configuração rápida. O seguinte guia de ação rápida mostra a desenvolvedores e não desenvolvedores como usar o DeepSeek OCR GitHub e outras opções.
Desenvolvedores-Experimente a API DeepSeek OCR em menos de 10 minutos
- O primeiro passo. Gere uma chave API a partir de "Conta" ou "Chave API" e defina "DEEPSEEK_API_KEY".
- Segundo passo. Modelos, dicas do sistema e padrões de conteúdo prontos para publicação em "/v1/chat/completions".
- Passo 3. Renderize a página PDF como PNG em DPI fixo e anexe base64 à "Mensagem".
- Passo 4. Solicite um JSON estrito ou Markdown e, em seguida, analise o campo "conteúdo" com segurança.
- Passo 5. Verifique campos, processe novas tentativas e persista em Trabalho ou Armazenamento.
Devs-executar a partir do GitHub (local)
- O primeiro passo. "Clone" o repositório em um computador pronto para CUDA e verifique a versão do driver ou do kit de ferramentas.
- Segundo passo. Crie o venv, execute "pip install -r requirements.txt", baixe "weights" e defina "MODEL_PATH".
- Passo 3. Converta PDFs em imagens com DPI consistente, execute "infer.py-Input page-Output-Format Markdown".
- Passo 4. "Latência", "VRAM" e "throughput" foram registrados e a precisão foi comparada com o OCR de linha de base.
Não-desenvolvedores-limpar o OCR de PDFs no PDFelement
- O primeiro passo. Primeiro, clique em "Criar PDF" e "A partir do scanner" para digitalizar. Em seguida, pressione o botão “Enhance Scan” e active as opções “Desskew” e “Text Sharpening”.
- Segundo passo. Pressione "Executar OCR", selecione "Idioma", selecione "Texto editável" ou "Texto pesquisável na imagem" e clique em "Aplicar".
- Passo 3. Use "AI Reading" ou "Leia em voz alta" para provar ouvindo e corrigir leituras erradas que você encontrou durante a reprodução.
- Passo 4. Agora, pressione o botão "Comentários" no painel esquerdo e adicione "Destaques", "Comentários" e "Adesivos" para visualização.
- Passo 5. Por fim, pressione "Exportar" para salvar um PDF pesquisável para entrega.
Parte 10. Considerações conhecidas (precisão, segurança, usabilidade)
Antes de adotá-lo totalmente na produção, é importante revisar alguns fatores práticos que afetam o desempenho da API DeepSeek OCR em uso real.
- Precisão: os resultados variam dependendo do layout da página e da qualidade da digitalização, então teste primeiro o desempenho em seu próprio corpus. Trabalhe com documentos representativos, incluindo tabelas e colunas, e rastreie erros, como divisões e mesclamentos.
- Segurança e conformidade: Revise o processamento, armazenamento e retenção de dados do fornecedor, evitando a transferência de arquivos sensíveis sem avaliação. Adicione revisões antes do upload, restrinja o acesso e registre as aprovações para atender às políticas internas e de auditoria.
- Disponibilidade e confiabilidade: os serviços podem sofrer interrupções ou limitações, portanto, adicione retentativas, rollbacks e rollbacks elásticos localmente. Monitore taxas de erro e atrasos, emita alarmes de falhas e defina manuais de operação claros para eventos.
- Taxa de transferência e escalamento: trate a taxa de transferência do cabeçalho apenas como taxa de transferência direcionada e benchmark em hardware com DPI fixo. Meça o número de páginas por hora, a utilização da GPU ou CPU e o custo e, em seguida, ajuste o tamanho do lote e do cache.
As pessoas também vão perguntar
-
O que é o DeepSeek OCR e por que a “compressão ótica” é importante?
O DeepSeek OCR comprime o conteúdo da página em tokens visuais compactos, preservando a estrutura e reduzindo o uso de tokens para modelos a jusante. Isso é importante porque permite uma maior cobertura de documentos dentro de limites contextuais fixos e reduz os custos de inferência, mantendo tabelas, listas e layouts intactos. -
Onde está o repo do DeepSeek OCR GitHub?
O repositório oficial fornece código, exemplos e referências para executar inferência local e pipelines de adaptação. Clone-o para avaliar a saída em relação ao seu OCR de linha de base, personalize dicas e exporte Markdown ou JSON para integração. -
Existe uma API DeepSeek OCR e é compatível com o OpenAI?
Há uma API que aceita solicitações de bate-papo estilo OpenAI com imagens ou páginas PDF renderizadas. Você pode solicitar JSON estrito ou Markdown e, em seguida, analisar o conteúdo da resposta usando bibliotecas padrão e fluxos de trabalho. -
Como posso usá-lo em PDFs?
Renderize cada página PDF como uma imagem com um DPI consistente, execute o vision OCR e, em seguida, conecte as páginas e pós-processe as tabelas e listas. Alternativamente, execute primeiro o OCR clássico no texto original e, em seguida, aplique o DeepSeek para semântica de layout, reparo de estrutura e geração de redução de preços. -
Posso executá-lo localmente com o Ollama?
As configurações da comunidade emparelham a saída do DeepSeek com modelos nativos da Ollama para perguntas e respostas, extração e validação. Os padrões típicos incluem painéis Streamlit, processadores de pastas de monitoramento e analisadores de documentos leves que não dependem de serviços de nuvem externos. -
Eu só preciso de OCR um PDF digitalizado com suporte multilíngue-o que é mais fácil?
Use o PDFelement para um fluxo de trabalho sem código que lida de forma confiável com remoção de skew, denoising e OCR multilíngue. Melhore a digitalização, selecione o idioma certo, use a leitura em voz alta ou a leitura com inteligência artificial para revisar, anotar e exportar um PDF limpo e pesquisável.