A tecnologia PDF avançou fortemente no reino da digitalização de arquivos ao longo das últimas décadas. O que antes era uma tarefa desafiadora pela preservação de dados e a habilidade de armazenar documentos para fácil recuperação agora se tornou algo comum. Um dos fatores-chave que direcionou essa mudança foi o OCR, ou reconhecimento de caractere óptico. Vamos ver por que o OCR desempenha um papel tão importante na digitalização do arquivo, como ele é aplicado como um processo, e como a precisão do OCR pode ser melhorada através de vários métodos.

Avaliação G2: 4,5/5 |

100% Seguro
Parte 1. Aplicação de OCR na digitalização de arquivos
OCR é essencialmente o processo de reconhecer, extrair e incorporar o conteúdo do texto de um documento baseado em imagem digital ou físico na camada de imagens existente. Essa tecnologia de dupla camada é suportada pelo PDF, fazendo dele um meio ideal para a digitalização de arquivos. Existem várias outras considerações que fazem do PDF o veículo perfeito para digitalizar arquivos de documentos.
1. Inovação na catalogação tradicional e metodologias de indexação
Catalogar e indexar geralmente andam lado a lado, mas são dois processos inteiramente diferentes. Enquanto catalogar é a organização de ativos ou itens de conteúdo, indexação é relacionado a recuperação de informação. Ambos são requeridos quando arquivando documentos, mídia áudio-visual, jornais, revistas, publicações acadêmicas e outros tipos de conteúdo. Catalogar te mostra o que está disponível, enquanto indexação oferece uma forma de encontrar a informação correta que você está procurando.
Converter documentos físicos ou digitalizados para PDF permite que o catálogo e a indexação aconteçam simultaneamente, usando a tecnologia OCR. O conteúdo digitalizado pode ser editável ou pesquisado, permitindo uma fácil catalogação de arquivos assim como indexação de arquivos. Consequentemente, OCR é, na verdade uma nova forma de catalogar e indexar arquivos de documentos, fazendo o processo acessível através de computadores.
2. Realizando a verdadeira recuperação de texto completo
Indexação manual é tipicamente propenso a erro humano, que pode variar de 3% até 30% dependendo da tarefa. Isso significa que documentos baseados em texto podem não ser propriamente indexados se o processo for conduzido manualmente. O mesmo vale para catalogação também, mas a um nível menor. Entretanto, com a ajuda do OCR, a conversão é possível até uma raxa de precisão de 98% a 99%. De fato, ele permite uma busca e recuperação completa de texto. Quando esse recurso é usado em conjunto com metadados e elementos de indexação, ele entrega um aumento para uma catalogação e sistema de indexação aprimorados.
3. Tecnologia PDF de dupla camada
Embora o entendimento geral é que OCR incorpora uma camada de texto em uma imagem existente, na realidade, ele é renderizado como texto invisível no PDF. Entretanto, esse texto pode agora ser selecionado e consequentemente pesquisável. No processo de digitalização de arquivos, o arquivista primeiramente vai verificar se a camada de texto digitalizada é consistente com o texto na imagem original. O passo de garantia da qualidade é crítica para precisão do texto renderizado. Essa modificação então serão armazenadas na cópia de OCR do arquivo, facilitando pesquisar com palavras-chave. Quaisquer erros de digitação deixados de lado durante essa checagem de garantia de qualidade vai tornar o documento não pesquisável para aquela palavra particular. Aí é onde os fatores de camadas entram. Ele permite que o arquivista confira visualmente se os caracteres reconhecidos pelo motor de OCR estejam consistentes com os caracteres do arquivo original baseado na imagem.
4. Expandindo o uso de documentos arquivados
Executar OCR em um documento PDF forma uma camada pesquisável, mas também torna o texto editável. Entretanto, para o propósito de arquivar e recuperar, um documento pesquisável é preferido por que as informações de indexação podem ajudar no retorno de resultados de buscas de texto. Por sua vez, ele permite que documentos OCR possam ser usados em uma variedade de cenários baseados se eles são editáveis ou buscáveis. Por exemplo, é muito mais fácil corrigir um pedaço de texto em um arquivo baseado em imagem usando OCR do que é para corrigir esse mesmo texto em uma ferramenta editora de imagem. OCR abre uma variedade dessas possibilidades de uso que técnicas de arquivamento tradicionais não conseguem competir.
Parte 2. Como melhorar a taxa de reconhecimento do OCR
A precisão de uma execução de OCR é dependente em várias considerações de softwares e manuais, e estas estão listadas abaixo. Cada um desses parâmetros permite os OCR serem mais precisos, e eles podem ser controlados pelo estágio pre-OCR ou pós-OCR, a depender do controle da qualidade.
1. O software correto - PDFelement
A extensão OCR no PDFelement é altamente precisa e funciona com múltiplos idiomas, mesmo simultaneamente. Em adição, PDFelement oferece conversão para tanto versões pesquisáveis, quanto para editáveis do arquivo PDF original. Ele também pode criar diretamente um PDF usando o resultado de uma digitalização, assim como converter formatos de arquivos não-texto para PDFs editáveis/pesquisáveis.
Avaliação G2: 4,5/5 |
100% Seguro
2. Os parâmetros de digitalização corretos
Quando digitalizando documentos, é importante definir os parâmetros corretos em suas configurações de digitalizador. Alguns deles são: O principal deles é orientação. Se certifique que o documento está alimentado no digitalizador no ângulo correto por que uma digitalização enviesada pode afetar seriamente a precisão do OCR.
3. Ajuste da resolução
A melhor resolução para OCR precisos é 300 dpi ou pontos por polegada. Essa densidade maior permite uma digitalização "mais apertada", permitindo que o motor do OCR trabalhe com o dobro dos pontos de referência quando comparado com 150 dpi.
4. Seleção de modo de cor
Para documentos descolorados ou antigos, o modo de cor recomendado é RGB para habilitar o digitalizador a capturar completamente os conteúdos do documento físico. No geral, entretanto, digitalizar em modo de tons de cinza é a melhor opção para precisão OCR. Embora o modo preto e branco ajuda a imagem ser digitalizada em uma taxa mais rápida, isso pode afetar a qualidade do reconhecimento do texto.
5. Ajuste de brilho e contraste
Para brilho, ambos os extremos - muito alto ou muito baixo - podem afetar negativamente a qualidade do OCR e precisão. Por essa razão, 50% é a configuração de brilho recomendada. Entretanto, isso também é dependente do próprio digitalizados, então uma fase inicial de tentativa e erro pode ser esperada.
Em termos de contraste, a maior configuração é geralmente preferida por que o OCR essencialmente trabalha analisando as áreas escuras e claras para identificar caracteres individuais. Regras então são aplicadas para combinar esses resultados com caracteres conhecidos, textos e números. Se o contraste entre a porção escura do texto é alta relativa aos arredores sem texto, o OCR é mais preciso.
6. Correção de imagem e descontaminação
Esses dois componentes impactam grandemente a qualidade da digitalização OCR. Correção de imagens cobre aspectos como um aumento na resolução, aplicação de correções de cores e tentativas de diferentes configurações de contrastes, enquanto a descontaminação envolve a remoção de caracteres sem-texto como ícones, imagens sem textos, caracteres não-usuais e assim por diante. Ambos são importantes por que eles habilitam que o motor do OCR leia o documento mais precisamente.
7. Revisão cuidadosa manual
Dependendo do quão preciso você quer que o resultado final seja, a revisão manual pode ser necessária ou não. Se a precisão é primordial, então isso pode ser um passo indispensável no processo de digitalização de arquivo. Ele essencialmente envolve verificação humana para garantir que os caracteres digitalizados foram reconhecidos corretamente no contexto da imagem digitalizada. É um processo tedioso e diligente, mas essencial em muitos casos.
PDFelement - O melhor software OCR para digitalização de arquivos
PDFelement oferece um motor de OCR altamente preciso, mas também traz várias outras vantagens a mesa quando se trata de digitalização de arquivos. Aqui estão alguns dos recursos que fazem dele o software perfeito para digitalizações e OCR PDFs.
Avaliação G2: 4,5/5 |
100% Seguro
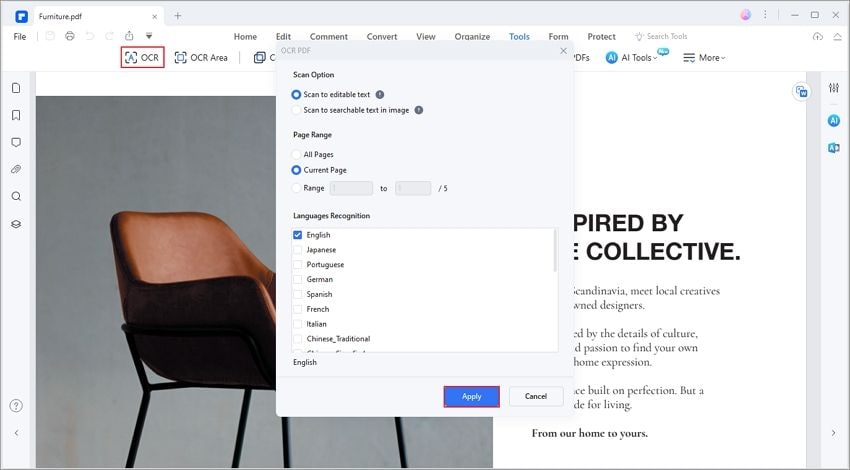
- Capacidades de edição total - Uma vez convertido em um PDF editável, um documento pode ser facilmente modificado usando as ferramentas de edição para imagens, textos, tabelas, gráficos, rodapés/cabeçalhos, marcas d'água, hyperlinks e outros conteúdos.
- OCR multi-idiomas - Se você tem um documento com mais de um idioma presente, você pode confiantemente usar o PDFelement para o processo OCR. Ele suporta mais de 20 idiomas, ajudando a melhorar a precisão geral do reconhecimento de texto.
- Processamento em lote - OCR pode ser feito em um lote de documentos, então economizando tempo no processo de arquivamento digital.
- Anotações - Arquivos convertidos podem ser anotados com notas, destacamentos e outros conteúdos, ajudando o processo de indexação. A lista de anotações e layout com guias do PDFelement facilita cruzar referências de textos quando pesquisando um tópico particular usando arquivos OCR.
- Assinatura digital e segurança - Arquivos podem ser assinados digital ou eletronicamente, assim como protegidos de visualização, ou edição não-autorizada usando criptografia baseada em senha. Isso ajuda a validar a autenticidade de um documento e previne quaisquer mudanças de serem feitas. Redação é outro recurso útil que usuários podem utilizar para prevenir informações sensíveis de serem pesquisadas.
- Organização de arquivo e página - Formas fáceis de dividir e mesclar arquivos, criar portfólios PDF, comparar documentos após OCR, adicionar/deletar/reordenar páginas, extrair páginas, etc.
- Redução do tamanho do arquivo - O recurso de otimização PDF do PDFelement ajuda arquivistas a armazenarem uma grande quantidade de informações de forma muito eficiente.
Por essas e outras razões, PDFelement é considerado um dos melhores editores PDF para OCR e tarefas relacionadas. O software também é o utilitário PDF premium mais acessível para pequenas empresas, assim como organizações de alto nível empresarial, fazendo dele uma solução viável para empresas, instituições educacionais, e todas as formas de entidades, desde governos aos setores públicos e privados.
 100% seguro | Sem publicidade |
100% seguro | Sem publicidade |