Neste artigo
- O que “extrair dados de um PDF” realmente significa
- Por que extrair dados de PDFs costuma ser difícil
- Método 1: Extraindo dados de formulários PDF preenchíveis
- Método 2: Extraindo dados de PDFs sem formulário
- Método 3: Extraindo dados de PDFs digitalizados
- Extração automatizada de dados de PDF: o que pode e o que não pode ser automatizado
- Extração de dados com IA em PDFs: como isso muda o processo
- Usando o PDFelement para extrair dados de PDFs
- Extraindo dados de PDF para planilhas e outras ferramentas
- IA vs. ferramentas de fluxo de trabalho (Power Automate e similares)
- Erros comuns na extração de dados de PDFs
PDFs fazem parte do trabalho diário da maioria das equipes, de faturas e contratos a resumos mensais. Ler é simples, mas transformar essas páginas em dados utilizáveis em planilhas leva tempo. As pessoas acabam copiando totais e datas manualmente — e é aí que surgem os gargalos. À medida que o volume de documentos cresce, a necessidade de extrair dados de arquivos PDF com precisão se torna mais urgente para a eficiência operacional e a clareza dos relatórios.
Por isso, as organizações agora exploram métodos manuais, automatizados e com IA para melhorar os resultados. Cada abordagem oferece níveis diferentes de velocidade, flexibilidade e controle. Além disso, escolher o método certo depende da complexidade dos documentos e das exigências do fluxo de trabalho.
Parte 1. O que “extrair dados de um PDF” realmente significa
À primeira vista, abrir um PDF e ler pode parecer suficiente. No entanto, visualizar um documento é muito diferente de realizar a extração de dados de arquivos PDF. Extrair dados, por outro lado, significa capturar valores, campos ou registros específicos e convertê-los em formatos estruturados e utilizáveis, como planilhas ou bancos de dados. O objetivo não é apenas ler o conteúdo, mas transformá-lo em informação acionável.
Visualizar vs. extrair dados
Quando você visualiza um PDF, rola as páginas manualmente. Você pode copiar e colar números ou digitá-los novamente em outro lugar. Em contraste, quando você obtém dados de documentos PDF por meio da extração, o sistema identifica automaticamente as informações desejadas. Ele detecta números de fatura, totais, datas, nomes ou linhas de tabela e os coloca em saídas organizadas. A extração se concentra em precisão, repetibilidade e usabilidade, e não apenas na legibilidade.
Dados estruturados vs. não estruturados em PDFs
Alguns PDFs seguem layouts previsíveis, com campos rotulados e tabelas bem definidas. Esses documentos estruturados permitem reconhecer padrões de dados repetidos com mais rapidez. Outros PDFs contêm texto livre, formatação irregular ou conteúdo digitalizado em imagem. Arquivos não estruturados exigem interpretação contextual das relações entre os elementos. Uma extração eficaz se adapta a ambos os formatos sem perder confiabilidade.
Casos de uso comuns em negócios e pesquisa
Para tornar isso mais concreto, os casos abaixo mostram onde a extração economiza esforço:

- Triagem de faturas: equipes financeiras extraem rapidamente totais, datas e nomes de fornecedores. Isso reduz redigitação e atrasos em pagamentos em períodos de pico.
- Documentação de RH: a equipe de RH captura facilmente dados de funcionários a partir de formulários e documentos assinados. Isso mantém os registros consistentes e ajuda em auditorias ou verificações de políticas.
- Revisão de contratos: equipes jurídicas extraem datas de renovação, cláusulas-chave e obrigações de contratos. Isso acelera revisões e evita prazos perdidos ou mal-entendidos caros.
- Atualizações de vendas: equipes de vendas extraem dados de clientes e preços de propostas e cotações. Isso mantém o CRM limpo e melhora previsões de negócios.
- Dados de pesquisa: pesquisadores extraem tabelas, referências e resultados de PDFs de artigos rapidamente. Isso acelera análises e melhora anotações para relatórios e publicações.


 Avaliação G2: 4,5/5 |
Avaliação G2: 4,5/5 | 100% Seguro
100% Seguro
Parte 2. Por que extrair dados de PDFs costuma ser difícil
Arquivos PDF parecem limpos e bem estruturados à primeira vista. No entanto, eles foram originalmente projetados para preservar o layout, não para armazenar dados em um formato flexível e reutilizável. Um PDF foca em manter fontes, espaçamento e design consistentes em diferentes dispositivos. Essa estabilidade visual facilita a leitura, mas frequentemente torna a extração de dados de arquivos PDF surpreendentemente complexa.
PDFs são feitos para layout, não para dados
Diferentemente de planilhas ou bancos de dados, PDFs nem sempre organizam informações em campos de dados claros. O que parece ser uma tabela organizada pode, na verdade, ser composto por caixas de texto separadas posicionadas cuidadosamente na página. Como resultado, os sistemas precisam interpretar a disposição visual antes de identificar valores significativos.
Diferentes tipos de PDF criam desafios diferentes
| Tipo de PDF | O que é | Principal desafio para extração |
| PDF digital | O texto é selecionável e geralmente é criado a partir de exportações de software. | Tabelas podem ser “visuais”, com colunas feitas por espaçamento, e não por estrutura real. |
| Formulário PDF preenchível | Contém campos de formulário para inserir nomes, datas e valores. | Campos mal projetados, nomes inconsistentes e camadas ocultas podem confundir a saída. |
| PDF digitalizado | Uma foto ou digitalização salva como imagem em PDF. | Exige OCR primeiro, e digitalizações de baixa qualidade reduzem a precisão do reconhecimento. |
Por que um método nunca funciona para todos os PDFs
Como os formatos variam muito, um único método de extração raramente se aplica a todos os cenários. Uma ferramenta que funciona perfeitamente em relatórios digitais pode ter dificuldades com recibos digitalizados. Por isso, fluxos de trabalho bem-sucedidos normalmente combinam várias técnicas, dependendo do tipo e da qualidade do documento.
Avaliação G2: 4,5/5 |100% Seguro
Parte 3. Método 1: Extraindo dados de formulários PDF preenchíveis
Formulários PDF preenchíveis armazenam as respostas dentro de campos nomeados, e não em texto comum de parágrafo. Cada campo mantém um rótulo e um valor, o que facilita coletar informações de forma consistente. Essa estrutura ajuda as ferramentas a extrair dados de formulários PDF com menos erros de formatação.
Exportar dados de formulário diretamente
Quando um PDF inclui campos de formulário reais, você pode exportar esses valores em minutos. A maioria das ferramentas de PDF oferece uma opção de exportação de formulário que cria um arquivo CSV, FDF ou XML. Depois de exportar, abra o arquivo em uma planilha e confirme se as colunas correspondem aos nomes dos campos.
Quando este método funciona melhor
Este método funciona melhor quando os documentos usam sempre o mesmo modelo de formulário. Ele é adequado para pesquisas, inscrições e checklists em que todos os campos são preenchidos de forma consistente. Ele funciona mal em PDFs digitalizados, imagens ou layouts sem campos interativos.
Parte 4. Método 2: Extraindo dados de PDFs sem formulário
PDFs sem formulário geralmente contêm dados em tabelas visíveis ou colunas alinhadas. Esses documentos parecem estruturados visualmente, mas o arquivo pode não armazenar campos reais. Ainda assim, é possível capturar valores se as linhas e colunas forem consistentes ao longo das páginas.
Copiar vs. extração estruturada
Copiar e colar pode funcionar para tabelas pequenas, mas a formatação se quebra facilmente. Ferramentas de extração estruturada tentam manter linhas, colunas e cabeçalhos alinhados corretamente. Quando a precisão é importante, a extração estruturada economiza tempo de limpeza em planilhas.
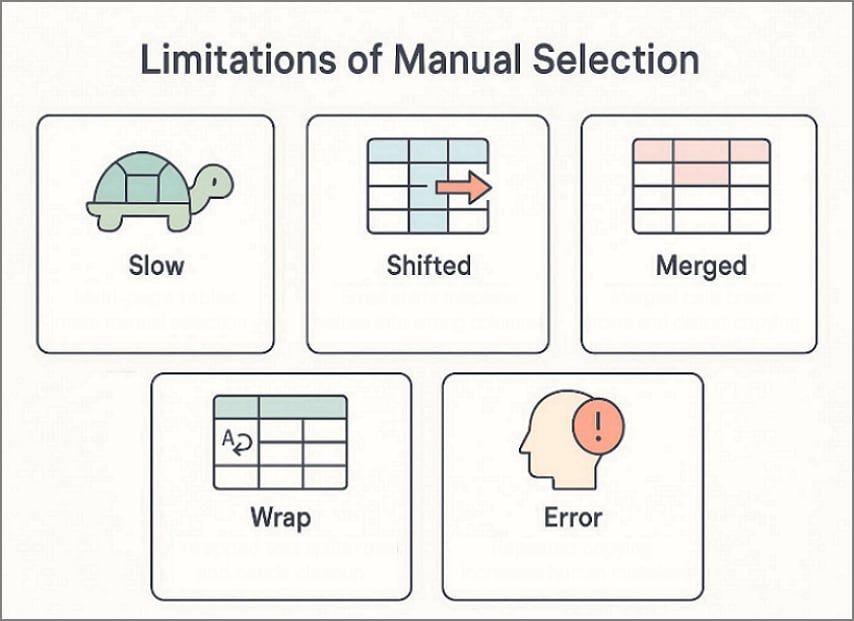
Limitações da seleção manual
- A seleção manual fica lenta quando as tabelas se estendem por várias páginas com frequência.
- Pequenas mudanças de alinhamento podem empurrar valores para colunas erradas com facilidade.
- Células mescladas frequentemente quebram a estrutura das linhas e distorcem os resultados copiados.
- Texto quebrado (quebra de linha) cria linhas divididas que exigem limpeza adicional depois.
- O erro humano aumenta quando você copia muitas tabelas repetidamente todos os dias.
Parte 5. Método 3: Extraindo dados de PDFs digitalizados
PDFs digitalizados normalmente são imagens de páginas, e não texto selecionável dentro do documento. Por isso, o software precisa “ler” a imagem e convertê-la em texto. Assim, o OCR permite extrair dados de PDFs digitalizados ao reconhecer caracteres impressos e padrões de layout.
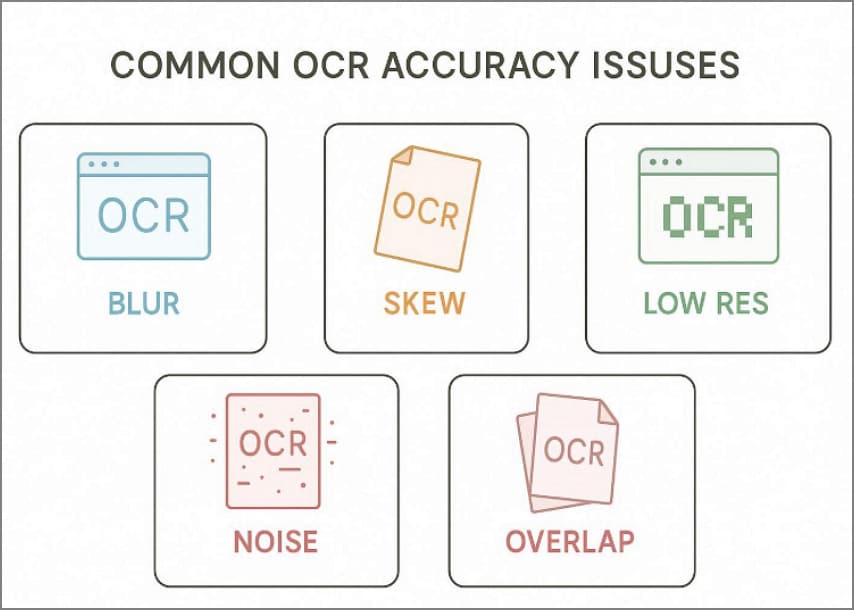
Problemas comuns de precisão do OCR
- Digitalizações borradas reduzem a confiança do OCR, dificultando a extração de dados de PDFs digitalizados.
- Páginas inclinadas desalinh am as linhas de texto, gerando palavras incorretas e linhas de tabela quebradas.
- Imagens de baixa resolução criam caracteres serrilhados; números podem ser lidos incorretamente ou “grudados”.
- Sombras e ruídos de fundo adicionam artefatos, confundindo pontuação, decimais e bordas de campos.
- Escrita à mão, carimbos e assinaturas sobrepõem o texto, reduzindo a precisão e aumentando correções manuais.
Quando o pré-processamento melhora os resultados
O pré-processamento melhora o OCR quando a qualidade da digitalização é irregular ou difícil de ler. Etapas como corrigir inclinação (deskew), reduzir ruído, aumentar contraste e recortar margens reduzem erros. Se as páginas estiverem giradas ou curvas, a correção ajuda o OCR a detectar melhor linhas e colunas.
Avaliação G2: 4,5/5 |100% Seguro
Parte 6. Extração automatizada de dados de PDF: o que pode e o que não pode ser automatizado
À medida que as organizações escalam o processamento de documentos, a extração automatizada de dados de PDF se torna uma necessidade operacional. Ela reduz a digitação manual, encurta o tempo de resposta e melhora a consistência em fluxos recorrentes. No entanto, embora a extração automática de dados de PDFs aumente muito a eficiência, ela funciona melhor dentro de limites bem definidos. Entender o que pode e o que não pode ser automatizado ajuda a definir expectativas realistas.
O que pode ser automatizado
Extração baseada em regras
A extração baseada em regras funciona bem com layouts previsíveis. Ela captura valores usando palavras-chave fixas, coordenadas ou rótulos consistentes de campos. Faturas padronizadas, modelos internos e relatórios recorrentes são candidatos ideais. Quando a estrutura permanece estável, a automação entrega resultados rápidos e confiáveis.
Fluxos de extração em lote
Fluxos em lote permitem processar grandes volumes de PDFs semelhantes de uma vez. As equipes podem enviar vários arquivos e extrair dados em um ciclo automatizado. Isso é eficaz para faturas mensais, sinistros ou extratos de fornecedores. Ambientes de alto volume se beneficiam de velocidade e menor manuseio repetitivo.
Onde a automação falha
A automação tem dificuldades quando os layouts variam muito entre diferentes modelos de documentos. Texto não estruturado, formatação inconsistente e escrita à mão frequentemente reduzem significativamente a precisão da extração. Digitalizações de baixa qualidade podem exigir correção manual após a conclusão do OCR. Campos ambíguos pedem interpretação contextual — algo que regras fixas não conseguem fornecer com confiabilidade.
Parte 7. Extração de dados com IA em PDFs: como isso muda o processo
Sistemas tradicionais tratam PDFs como imagens fixas com layout “travado”. Em contraste, a extração de dados com IA em PDFs muda o processamento de documentos de forma prática. Em vez de ler coordenadas, a IA avalia estrutura, relações e significado contextual. Essa mudança transforma a extração de uma captura mecânica em compreensão inteligente de documentos.
Como a IA interpreta a estrutura do documento
A IA analisa espaçamento, alinhamento, hierarquia tipográfica e agrupamento de conteúdo em conjunto. Ela detecta títulos, tabelas, totais e rótulos por pistas estruturais. Em vez de depender de posições fixas de pixels, ela estuda relações lógicas. Como resultado, a extração permanece estável mesmo quando o layout muda inesperadamente. Veja o que a IA considera dentro de um documento durante a interpretação:
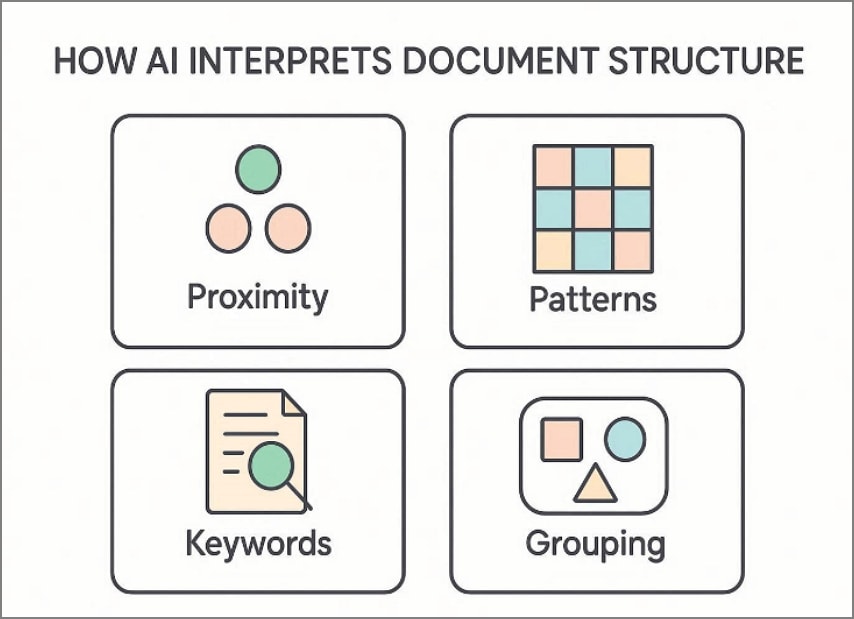
- Proximidade do texto entre rótulos e valores em seções e colunas.
- Padrões repetidos que indicam tabelas, itens de linha ou listas estruturadas.
- Palavras-chave ao redor que esclarecem totais, impostos, datas e identificadores.
- Agrupamentos visuais que conectam campos relacionados no mesmo contexto.
Extraindo significado, não apenas texto
A automação mais antiga capturava caracteres sem entender o propósito do negócio. Quando ferramentas com IA extraem dados do conteúdo do PDF, elas interpretam a intenção usando o contexto. Por exemplo, “Total” normalmente indica o valor a pagar próximo desse rótulo. O contexto reduz confusões entre número de fatura e campos de referência semelhantes. Assim, as saídas extraídas exigem menos correções durante validação e relatórios.
Usando IA para lidar com layouts inconsistentes
Em fluxos reais, fornecedores raramente mantêm padrões de formatação idênticos de forma consistente. Tabelas mudam de posição, cabeçalhos se movem e fontes variam entre versões do documento. Por isso, sistemas baseados em regras frequentemente falham quando modelos mudam sem aviso prévio. A IA, por sua vez, se adapta usando relações entre rótulos e valores, e não coordenadas.
| Extração baseada em regras | Extração baseada em IA |
| Depende de posições fixas e modelos rígidos para capturar campos. | Usa estrutura e contexto para identificar campos com mais confiabilidade. |
| Quebra quando o layout muda levemente entre fornecedores e versões. | Permanece útil quando colunas se deslocam ou cabeçalhos mudam de lugar. |
| Captura strings de texto sem interpretar o significado no documento. | Extrai valores relevantes ao entender rótulos e relações. |
Parte 8. Usando o PDFelement para extrair dados de PDFs
PDFs parecem organizados, mas extrair dados limpos pode ficar frustrante rapidamente. Formulários podem exportar campos, tabelas podem “quebrar” e digitalizações precisam de OCR preciso. Em vez de alternar entre ferramentas, muitas equipes preferem um único fluxo para tudo. É aí que o PDFelement entra, ajudando você a extrair dados de campos de formulário em PDF e de outros layouts.
Além disso, os usuários podem puxar dados de formulários preenchíveis, tabelas ou páginas digitalizadas com mais confiabilidade. Depois, é possível revisar resultados, exportar arquivos estruturados e repetir o processo com mais rapidez.
Extrair dados de formulários e tabelas em PDF
Formulários PDF preenchíveis armazenam respostas em campos nomeados, e não em blocos de texto comum. PDFs com tabelas parecem estruturados, mas geralmente não têm tags de campo prontas para exportação. O PDFelement lida com ambos ao exportar campos ou extrair tabelas selecionadas rapidamente. Use-o para faturas, inscrições e relatórios em que colunas e rótulos se repetem com consistência entre arquivos. Siga o guia passo a passo abaixo para exportar dados limpos e conferir os resultados:
Avaliação G2: 4,5/5 |100% Seguro
Etapa 1Abra o PDF no PDFelement para prosseguir
Para começar, abra o PDFelement e selecione “Abrir PDF” no painel principal.
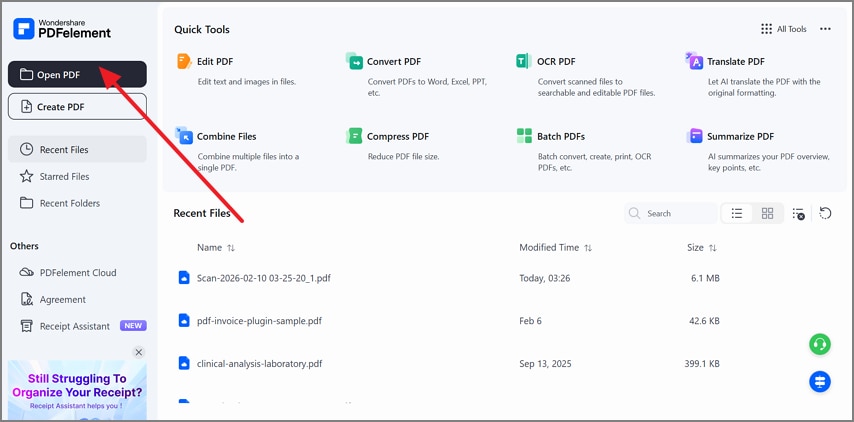
Etapa 2Extraia dados com a ferramenta de Formulário
Em seguida, vá até a opção “Formulário” na barra lateral esquerda e selecione “Três pontos” para continuar. No menu suspenso, escolha “Extrair dados” para iniciar o processo de captura estruturada.
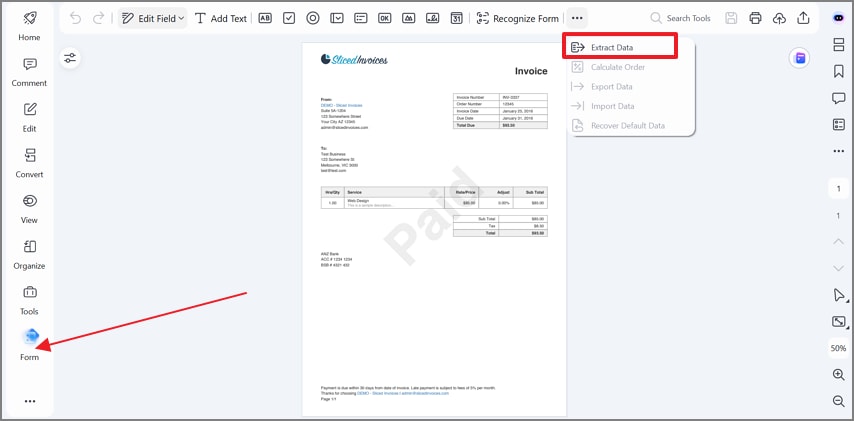
Etapa 3Escolha o modo de extração
Nesta etapa, escolha “Extrair dados com base na seleção” na caixa de diálogo e clique em “Aplicar”. Esse modo permite controle preciso, extraindo apenas os campos que você seleciona manualmente.
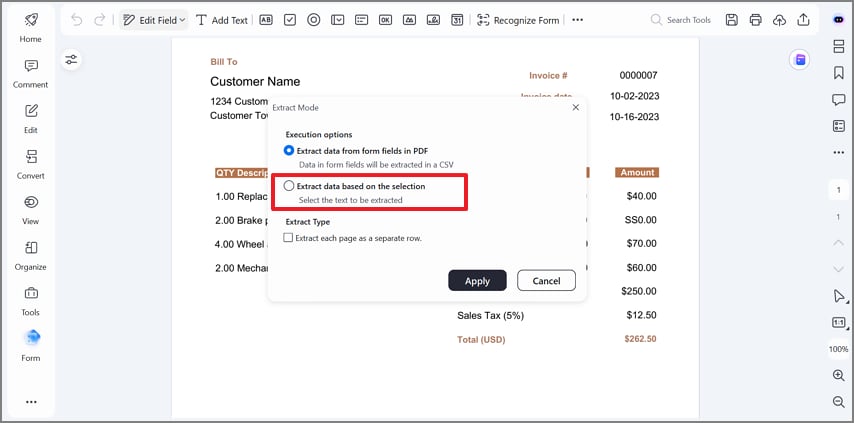
Etapa 4Marque os campos necessários e aplique a extração
Depois de selecionar o modo, desenhe caixas de seleção ao redor dos campos necessários, como itens de linha, totais ou valores de imposto, e clique em “Aplicar”.
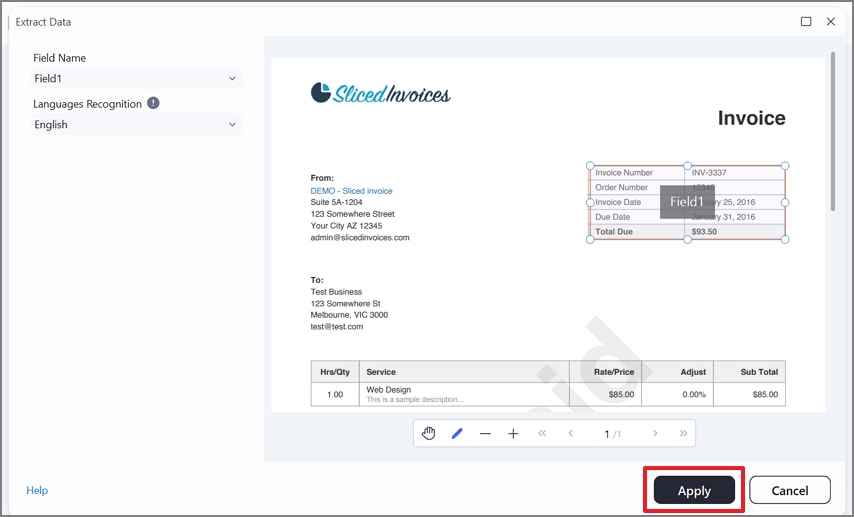
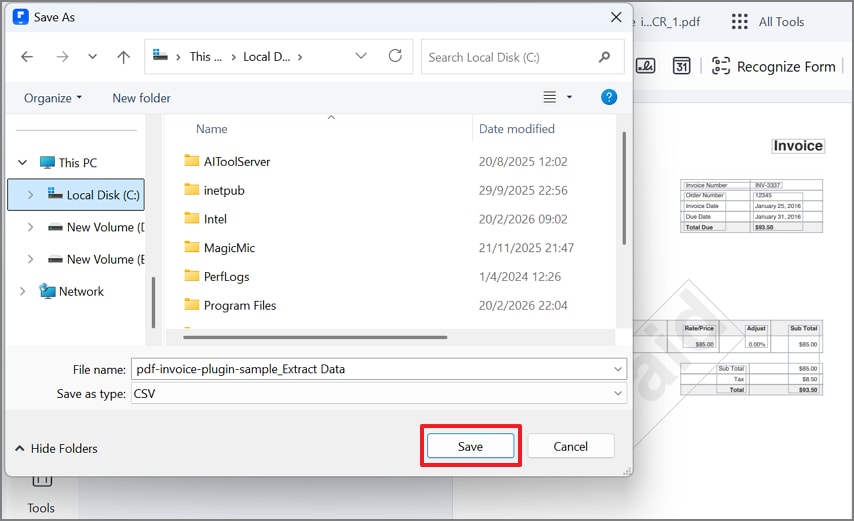
Etapa 5Exporte os dados extraídos como CSV e salve
Ao clicar em “Aplicar”, o PDFelement abre automaticamente a janela “Salvar como”. Agora, selecione o formato desejado, como CSV, e clique em “Salvar” para exportar os dados para o seu dispositivo.
Extração com OCR para PDFs digitalizados
PDFs digitalizados são imagens, então você não consegue copiar texto diretamente. O OCR converte a imagem em texto selecionável, melhorando a busca e a precisão da extração. Assim, digitalizações melhores produzem resultados melhores — especialmente para tabelas e números. O pré-processamento corrige inclinação, desfoque e ruído, reduzindo erros durante o reconhecimento e a exportação. Siga as etapas abaixo para aplicar este método no PDFelement:
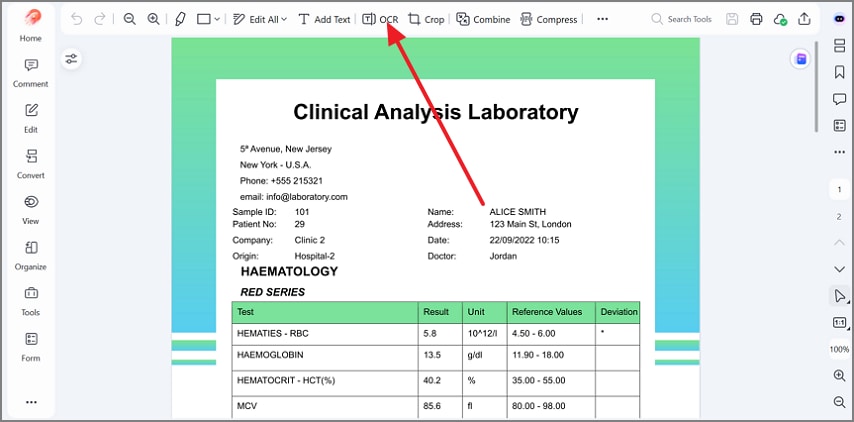
Etapa 1Acesse a ferramenta de OCR para continuar
Primeiro, abra o PDF digitalizado no PDFelement e clique em “OCR” na barra superior.
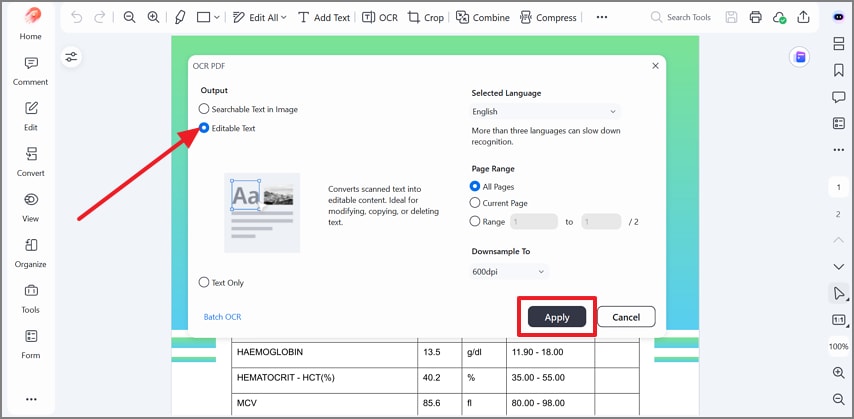
Etapa 2Escolha Texto editável e aplique o OCR
Em seguida, selecione “Texto editável” na janela do OCR e confirme o idioma e o intervalo de páginas. Depois, clique em “Aplicar” para converter a digitalização em texto editável e selecionável.
Avaliação G2: 4,5/5 |100% Seguro
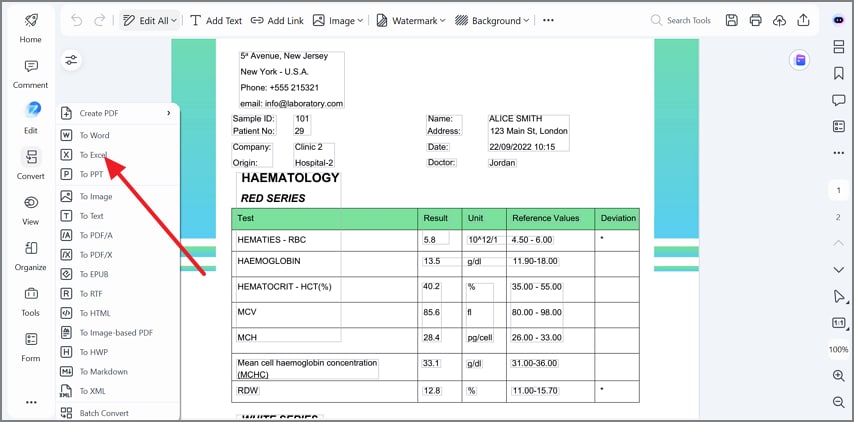
Etapa 3Converta o arquivo com OCR para o formato Excel
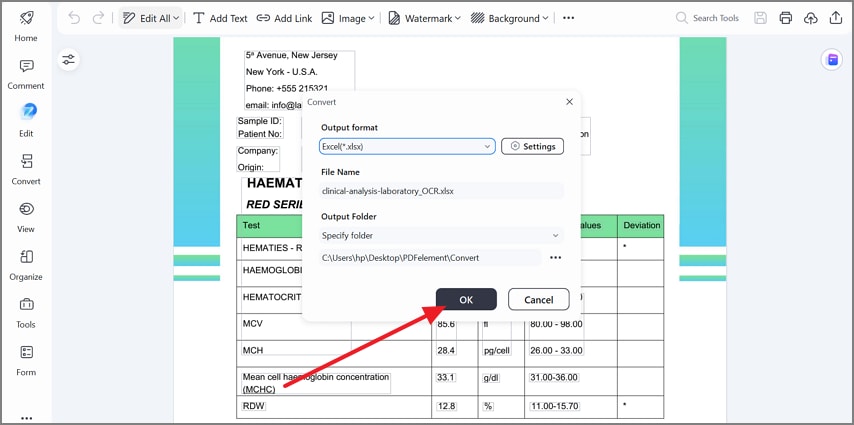
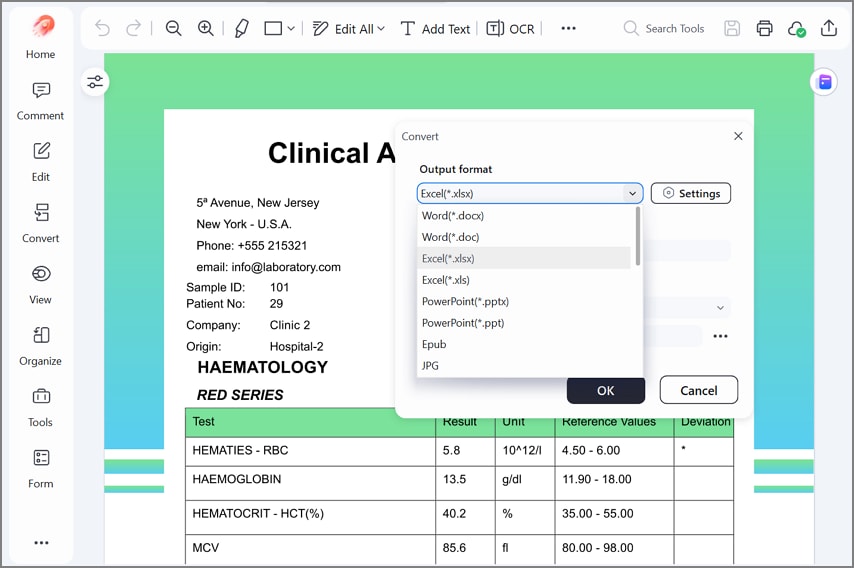
Depois, vá até “Converter” e escolha “Para Excel” no menu suspenso. Isso prepara os dados de tabela para extração em planilha e edição estruturada.
Etapa 4Salve como XLSX e verifique a precisão da planilha
Por fim, mantenha “Excel (*.xlsx)” como formato de saída, escolha uma pasta e clique em “OK”. Em seguida, abra a planilha exportada e confira rapidamente colunas, totais e unidades.
Extração em lote para layouts repetidos
A extração em lote processa vários PDFs de uma só vez usando um padrão de seleção repetido. Ela funciona melhor quando os documentos compartilham o mesmo modelo e estrutura de página. Você define as regiões uma vez e aplica a extração em toda a pasta. Esse método acelera relatórios mensais, processamento de faturas e auditorias, mantendo colunas consistentes para análise. Siga as etapas abaixo para ver como funciona:
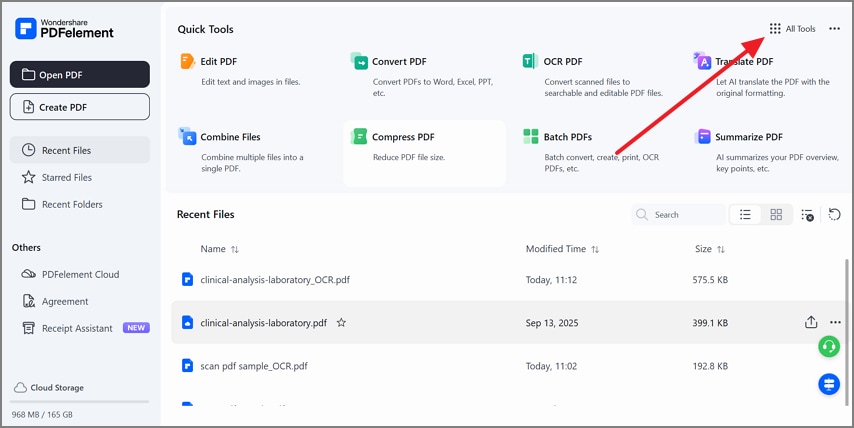
Etapa 1Acesse “Todas as ferramentas” para usar recursos em lote
Para começar, abra o PDFelement e escolha “Todas as ferramentas”.
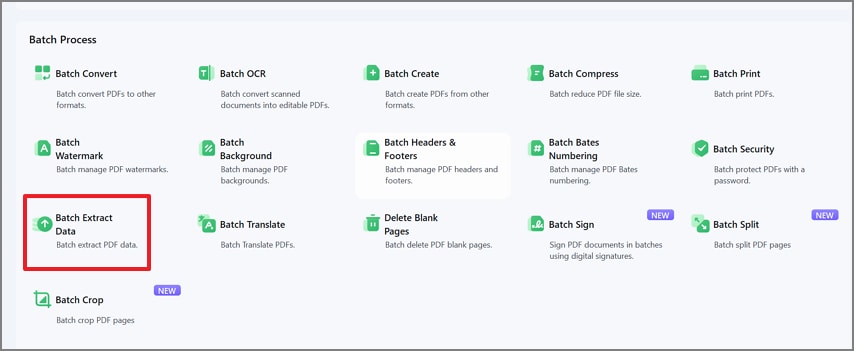
Etapa 2Selecione “Extrair dados em lote” no processamento em lote
Depois, na janela de “Processo em lote”, escolha “Extrair dados em lote” para iniciar a ferramenta de extração em massa.
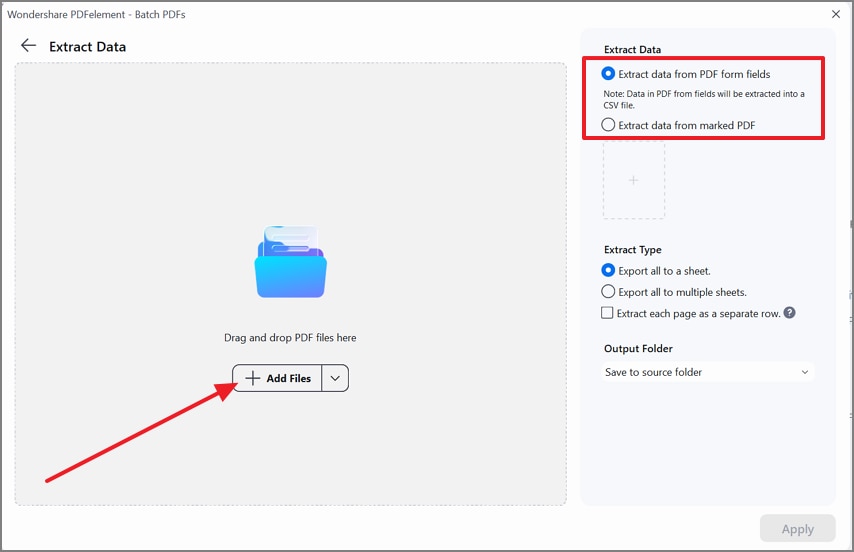
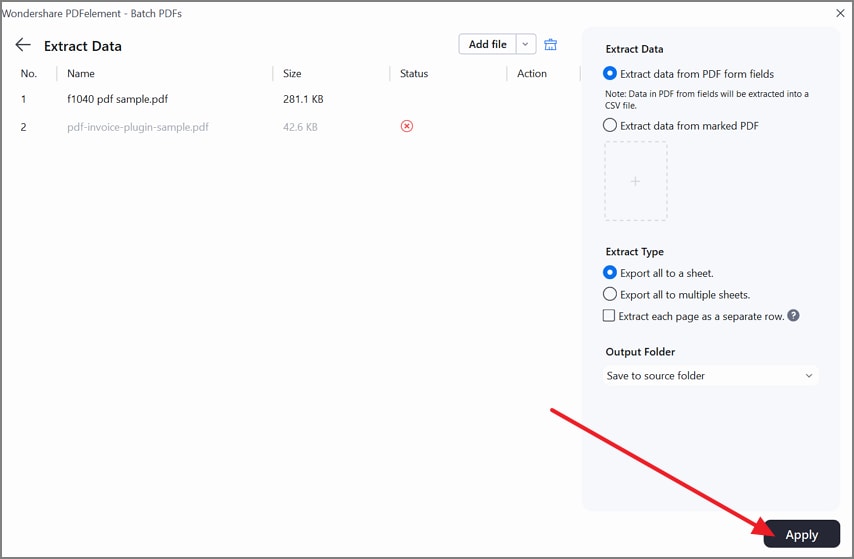
Etapa 3Adicione PDFs e defina as opções de saída
Em seguida, clique em “Adicionar arquivos” e carregue seus PDFs de uma vez. No painel da direita, selecione “Extrair dados de campos de formulário PDF” ou “Extrair dados de PDF marcado”, escolha o formato de exportação e confirme a pasta de destino.
Etapa 4Aplique a extração em lote e valide as colunas de saída
Por último, clique em “Aplicar” para gerar a planilha de saída. Depois, abra o arquivo exportado e verifique rapidamente se as colunas principais batem entre os documentos.
Avaliação G2: 4,5/5 |100% Seguro
Recursos de IA
Depois de extrair dados de um PDF para o Google Sheets, os recursos de IA abaixo ajudam a verificar e reutilizar resultados com mais rapidez:
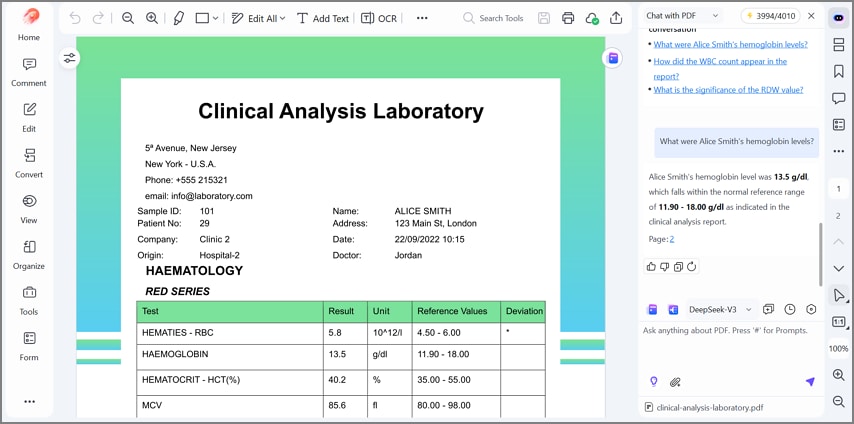
Chat com PDF: Faça perguntas instantâneas sobre totais, datas, fornecedores e campos ausentes no PDF. O recurso destaca as linhas de suporte para você validar números antes de compartilhar resultados.
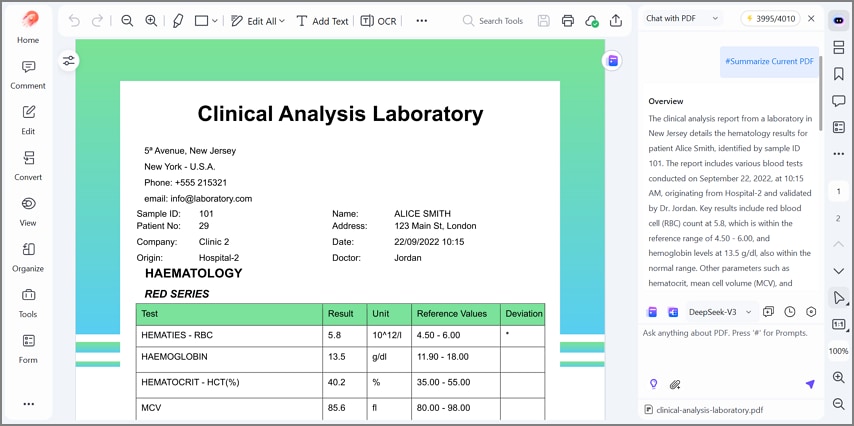
Resumo com IA: Resuma PDFs longos em pontos-chave, decisões e números importantes de forma rápida e clara. Ele explica tabelas, destaca tendências, anomalias e itens que exigem revisão humana.
Exportar resultados estruturados para reutilização: Exporte saídas como CSV ou Excel com cabeçalhos estáveis para reutilizar em qualquer lugar. Estrutura consistente reduz limpeza e facilita relatórios, automação e importações futuras.
Alternar modelos de IA: Alterne entre GPT-4o, Gemini e DeepSeek para cruzar respostas com mais confiabilidade. Comparar saídas aumenta a confiança, encontra erros e reduz pontos cegos de um único modelo.
Parte 9. Extraindo dados de PDF para planilhas e outras ferramentas
As opções de exportação transformam tabelas extraídas em planilhas que as equipes podem validar rapidamente. Você pode extrair dados de um PDF para o Google Sheets exportando como CSV e, em seguida, importando. Exportações para Excel funcionam bem para limpeza offline, fórmulas e relatórios com tabelas dinâmicas.
- Escolha CSV ou XLSX quando precisar de colunas confiáveis e cabeçalhos preservados.
- Importe o arquivo no Sheets e congele o cabeçalho para facilitar a conferência.
- Aplique tipos de dados para datas e moedas para evitar erros de ordenação depois.
Preparando dados extraídos para automação posterior
A automação precisa de colunas consistentes, cabeçalhos estáveis e estruturas de linhas previsíveis em todas as execuções. Comece renomeando campos de forma clara e remova duplicatas criadas por cabeçalhos repetidos.
- Padronize formatos de data e decimais para evitar que scripts falhem inesperadamente.
- Adicione uma coluna de ID único, permitindo mesclagens seguras entre vários arquivos.
- Valide totais em relação ao PDF e sinalize discrepâncias para revisão rápida.
Por que uma extração limpa importa no fluxo downstream
Uma extração “suja” cria erros silenciosos que se espalham para relatórios, painéis e pagamentos. Saídas limpas reduzem retrabalho, aceleram aprovações e melhoram trilhas de auditoria entre departamentos.
- Tabelas limpas melhoram a correspondência em CRMs, ERPs e conciliações financeiras.
- Colunas precisas reduzem correções manuais ao conectar fluxos no Power Automate.
- Dados consistentes sustentam decisões mais rápidas porque KPIs permanecem comparáveis ao longo do tempo.
Parte 10. IA vs. ferramentas de fluxo de trabalho (Power Automate e similares)
Ferramentas de IA se concentram em entender e limpar documentos, enquanto ferramentas de fluxo de trabalho se concentram em roteamento e automação. Quando as pessoas perguntam como o Power Automate extrai dados de PDFs, a resposta real é simples: o Power Automate pode mover arquivos e acionar ações, mas a qualidade da extração é o que define o sucesso.
O que o Power Automate faz bem
- Roteia PDFs de e-mail, OneDrive e SharePoint para fluxos padronizados de forma automática e segura.
- Dispara aprovações, alertas e logs quando novos documentos PDF chegam.
- Insere valores extraídos em tabelas do Excel, bancos de dados ou campos de CRM sem redigitar.
- Agenda fluxos recorrentes, garantindo processamento consistente entre equipes e fusos horários.
Por que a qualidade da extração ainda importa
- A automação amplifica erros; um dígito errado pode distorcer relatórios downstream rapidamente.
- Colunas deslocadas e células mescladas quebram o mapeamento de campos, causando preenchimentos incorretos (muitas vezes silenciosamente).
- OCR ruim interpreta totais de forma errada, aumentando exceções, correções manuais e atrasos de conciliação.
- Extração limpa melhora auditorias, compliance e a confiança nas decisões.
Quando dados do PDF precisam ser preparados antes da automação
- Modelo pronto: antes do Power Automate, extraia dados do PDF e padronize modelos e nomes de campos.
- Limpeza de digitalização: PDFs digitalizados precisam de correção de inclinação e ajustes de contraste antes do OCR.
- Higiene de tabelas: tabelas bagunçadas exigem cabeçalhos normalizados e quebras de linha corrigidas.
- Controle de layout: layouts variáveis podem precisar de pré-extração em uma ferramenta de PDF antes da automação.
Parte 11. Erros comuns na extração de dados de PDFs
Antes de começar a extrair dados de arquivos PDF, evite suposições que causam erros caros. Os erros comuns abaixo explicam por que a precisão cai e o retrabalho aumenta rapidamente:

- Tratar tudo igual: muitas equipes tratam todo PDF como se fosse idêntico, o que causa falhas. Tipos diferentes de PDF exigem métodos diferentes para resultados consistentes e precisos.
- Dependência de OCR: equipes confiam apenas no OCR mesmo com baixa qualidade de texto. Sem revisão, erros do OCR se espalham rapidamente para relatórios e registros financeiros.
- Expectativa de automação total: alguns esperam automação completa, assumindo que a IA resolverá todas as exceções. Na prática, layouts incomuns e campos ausentes ainda exigem julgamento humano.
- Ignorar validação: muitos pulam checagens de validação, e totais/datas incorretos passam despercebidos. Regras básicas e conferências cruzadas aumentam a precisão antes de exportar.
- Ferramenta inadequada: organizações escolhem ferramentas sem avaliar complexidade e variabilidade dos documentos. Isso gera saídas inconsistentes e correções manuais frequentes.
Perguntas frequentes
-
Como eu extraio dados de um PDF?
Use uma ferramenta de PDF para selecionar tabelas, exportar campos de formulário ou executar OCR quando necessário. Depois, verifique colunas, corrija quebras de linha e salve resultados limpos como CSV ou Excel. -
A IA consegue extrair dados de PDFs digitalizados?
Sim. A IA pode extrair dados de PDFs digitalizados após o OCR converter imagens em texto pesquisável. A precisão melhora com digitalizações nítidas, idioma correto e validação cuidadosa dos números. -
Qual é a melhor ferramenta para extração de dados de PDF?
A melhor ferramenta é a que combina com seus arquivos e oferece exportação de formulários, extração de tabelas, OCR e processamento em lote. Se você precisa de um fluxo único, o PDFelement reúne extração, OCR e exportação para planilhas em um só lugar. -
A extração automatizada de dados de PDF é confiável?
Ela é confiável quando os layouts permanecem consistentes e as digitalizações são claras em lotes. Fica menos confiável com modelos mistos, tabelas mescladas, escrita à mão ou mudanças de formatação ao longo do tempo. -
Como extraio dados de PDFs para planilhas?
Exporte os dados extraídos como CSV ou XLSX e abra no Excel ou Google Sheets. Limpe cabeçalhos, defina tipos de dados e valide totais para que fórmulas e automações funcionem corretamente depois.
Conclusão: escolhendo a abordagem certa para extração de dados de PDF
Escolher a melhor abordagem começa identificando primeiro o tipo de PDF. Formulários exportam campos com mais limpeza, enquanto tabelas exigem seleção estruturada para precisão. Documentos digitalizados precisam de OCR antes da extração para resultados confiáveis. Automação e IA reduzem esforço, mas a revisão evita erros downstream. Em colaboração, extraia dados de PDF para o Google Sheets após limpar cabeçalhos. Para um fluxo consistente em diferentes casos, o PDFelement segue sendo uma escolha prática.