Neste artigo
- O LibreOffice pode realizar OCR nativamente?
- Método 1: Usando o LibreOffice com ferramentas gratuitas de OCR online
- Método 2: Explorando a extensão LibreOCR
- Limitações das soluções alternativas de OCR no LibreOffice
- Método 3: A melhor alternativa dedicada – Wondershare PDFelement
- Como realizar OCR com o PDFelement (passo a passo)
- Vantagens de usar o PDFelement ao invés do LibreOffice para OCR
- Comparação: Capacidades de OCR do LibreOffice vs. PDFelement
- Melhores práticas para resultados de OCR de alta qualidade
- Conclusão
O LibreOffice é amplamente reconhecido como uma das suítes de escritório gratuitas e de código aberto mais poderosas disponíveis atualmente. Milhões de usuários dependem de seus aplicativos – Writer, Calc, Impress e Draw – para a gestão diária de documentos. No entanto, ao lidar com documentos digitalizados, os usuários frequentemente enfrentam um obstáculo comum: o Reconhecimento Óptico de Caracteres (OCR).
Se você está tentando editar um documento digitalizado, provavelmente está procurando por uma solução confiável de OCR no LibreOffice. O OCR é a tecnologia fundamental que transforma uma imagem de texto (como um papel digitalizado ou fotografia) em texto editável e reconhecível por máquina. Sem ele, um PDF digitalizado é basicamente apenas uma imagem bloqueada.
Neste guia completo, vamos explorar exatamente como você pode extrair texto de imagens usando o LibreOffice, discutir extensões populares como o LibreOCR, e apresentar alternativas dedicadas para tornar sua gestão de documentos mais fácil.


 Avaliação G2: 4,5/5 |
Avaliação G2: 4,5/5 | 100% Seguro
100% Seguro
O LibreOffice pode realizar OCR nativamente?
A resposta curta é:Não, o LibreOffice não possui um mecanismo de OCR nativo embutido.
Quando você abre um PDF digital (baseado em texto) no LibreOffice Draw, o software geralmente identifica os blocos de texto, permitindo edições básicas. No entanto, se você abrir um PDF digitalizado, o LibreOffice Draw tratará toda a página como um único arquivo de imagem. Você pode redimensionar ou mover a imagem, mas não é possível clicar no texto para alterar palavras, excluir frases ou modificar a fonte.
Por ser de código aberto, a comunidade desenvolveu várias soluções alternativas para contornar essa limitação. Para alcançar OCR em PDF no LibreOffice, você basicamente tem duas opções principais:
- Usar uma ferramenta externa (como um aplicativo web) para converter o documento antes de levá-lo ao LibreOffice.
- Confiar em uma extensão de código aberto, embora estas possam ser bastante técnicas para configurar.
Método 1: Usando o LibreOffice com ferramentas gratuitas de OCR online
A solução alternativa mais comum e fácil de usar para aqueles que querem manter a edição final no LibreOffice é uma abordagem híbrida. Isso envolve usar um serviço de OCR gratuito online para fazer o trabalho pesado e, em seguida, utilizar o LibreOffice Writer para formatar e finalizar o documento.
Veja o fluxo de trabalho passo a passo:
Passo 1Abra seu documento
Comece abrindo o LibreOffice. Clique em "Arquivo" no menu superior, selecione "Abrir" e localize seu arquivo PDF. Se for um documento digitalizado, o Draw exibirá o conteúdo como uma imagem única. Isso confirma que o OCR é necessário.


Passo 2Utilize um serviço externo de OCR
Como o LibreOffice não possui OCR, você precisa utilizar temporariamente uma ferramenta externa. Encontre um serviço respeitável e gratuito de OCR online, faça o upload do PDF digitalizado. A ferramenta baseada na nuvem processará as imagens e extrairá o texto.

Passo 3Importe para o LibreOffice Writer
Quando o serviço online finalizar seu processo, baixe o arquivo de texto gerado (geralmente um arquivo .txt ou .docx). Volte ao LibreOffice, abra o Writer, clique em "Arquivo" e selecione "Abrir".

Localize o arquivo de texto que acabou de baixar e abra-o. Agora você verá o texto bruto extraído da sua digitalização.

Passo 4Edite e salve
Agora é possível editar o texto, mudar as fontes, adicionar formatação e reconstruir o layout do documento. Quando estiver satisfeito, recomenta-se salvar seu trabalho como um arquivo ODT (formato nativo do LibreOffice) para futuras edições.
Por fim, para compartilhar o documento, você pode exportá-lo novamente para PDF. Clique em "Arquivo" > "Exportar" > "Exportar como PDF". Selecionar "PDF Híbrido" é uma ótima opção, pois insere o arquivo ODT dentro do PDF, facilitando edições futuras no LibreOffice.

Método 2: Explorando a extensão LibreOCR
Para usuários que desejam tudo integrado ao ambiente de trabalho, sem depender da nuvem, a comunidade open-source desenvolveu extensões. A mais famosa nas discussões é LibreOCR.
O que é LibreOCR?
O LibreOCR é uma extensão desenvolvida para trazer capacidades de OCR diretamente para o LibreOffice. Ela não reinventa a roda, servindo como uma interface gráfica (GUI) para o Tesseract, um dos mais poderosos motores de OCR de código aberto originalmente desenvolvido pela HP e mantido pelo Google.
Como funciona
Quando instalada com sucesso, os usuários podem teoricamente acionar um macro ou botão da extensão que envia os dados da imagem para o Tesseract, que processa o texto e o devolve para o documento do LibreOffice.
O Ponto Crítico
Embora a ideia de uma extensão LibreOCR seja ótima, na prática pode ser complicada. Instalar o Tesseract requer conhecimento de linha de comando em alguns sistemas operacionais. Além disso, integrá-lo ao LibreOffice costuma exigir scripts em Python, configuração de variáveis de ambiente do sistema e lidar com problemas de compatibilidade de versões. Para o usuário médio que só quer editar um PDF, esse método geralmente é complexo e sujeito a falhas em atualizações de software.
Limitações das soluções alternativas de OCR no LibreOffice
Seja usando uma ferramenta online ou tentando configurar uma extensão Tesseract, depender do LibreOffice para OCR traz desvantagens claras:
- Perda de Formatação: Extratores de texto externos geralmente removem a formatação. Você pode obter o texto, mas tabelas, colunas, cabeçalhos e marcadores são frequentemente destruídos, exigindo horas de reconstrução manual no Writer.
- Riscos de Segurança: Enviar documentos confidenciais, registros médicos ou arquivos pessoais para sites gratuitos de OCR representa risco significativo de privacidade de dados.
- Barreiras multilíngues: Lidar com documentos em vários idiomas ou conjuntos de caracteres complexos (como línguas asiáticas ou o árabe) frequentemente faz com que ferramentas gratuitas gerem resultados ininteligíveis.
Método 3: A melhor alternativa dedicada – Wondershare PDFelement
Se seu principal objetivo é editar PDFs digitalizados de forma rápida, precisa e segura, optar por uma ferramenta dedicada ao invés de soluções alternativas no LibreOffice é a escolha mais lógica.Wondershare PDFelement é um editor de PDF profissional equipado com um avançado mecanismo de OCR integrado.
Diferente do fluxo de trabalho fragmentado do LibreOffice, o PDFelement faz tudo em um único local. Ele usa Inteligência Artificial para analisar documentos digitalizados, reconhecer texto (mesmo em digitalizações de baixa qualidade) e sobrepor o texto editável exatamente onde estava a imagem original. Isso preserva o layout, fontes e formatação do documento.
Avaliação G2: 4,5/5 |100% Seguro
Como realizar OCR com o PDFelement (passo a passo)
Usar o PDFelement para realizar OCR é extremamente fácil. Veja como transformar um documento digitalizado em um arquivo totalmente editável em poucos minutos:
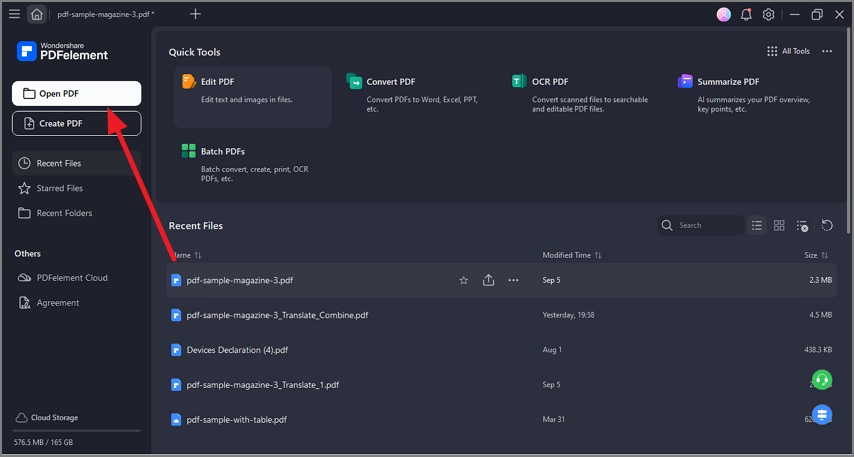
Passo 1Abra o arquivo
Abra o PDFelement e carregue o PDF digitalizado clicando no botão 'Abrir Arquivo' na tela inicial.
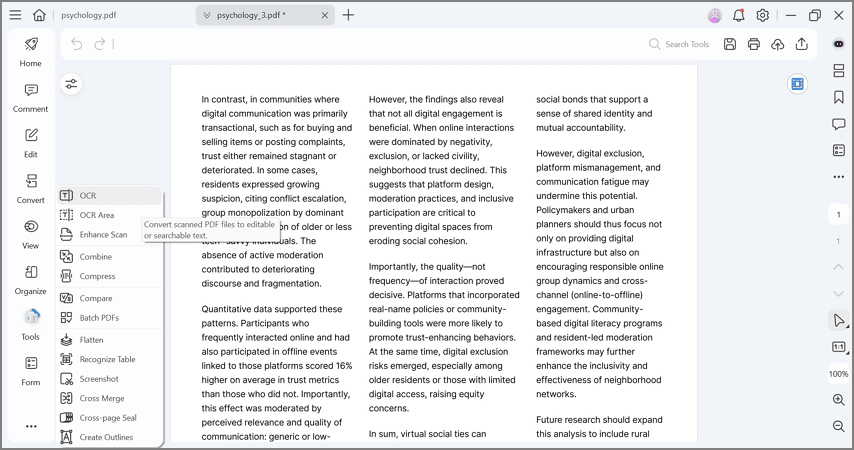
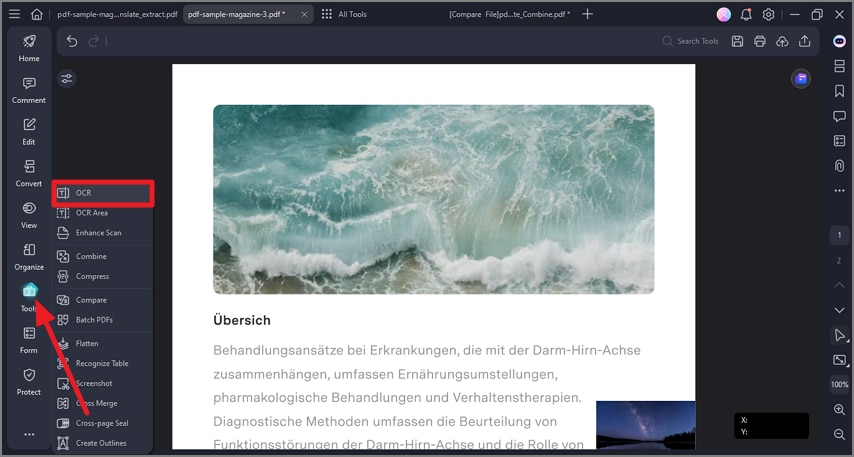
Passo 2Acesse a ferramenta OCR
Como o PDFelement detecta que o arquivo é uma digitalização, muitas vezes ele apresenta um aviso automaticamente. Alternativamente, você pode clicar na aba "Ferramentas" no menu superior e selecionar o botão "OCR".
Passo 3Escolha as opções de digitalização
Uma janela de configuração será exibida. Selecione "Digitalizar para texto editável". Isso garante que o texto reconhecido possa ser modificado, excluído ou adicionado, e não apenas pesquisável.
Avaliação G2: 4,5/5 |100% Seguro
Passo 4Selecione o idioma
Para máxima precisão, clique em "Alterar idioma" e selecione o(s) idioma(s) presente(s) no documento. O poderoso mecanismo do PDFelement suporta mais de 20 idiomas, sendo ideal para documentos internacionais.
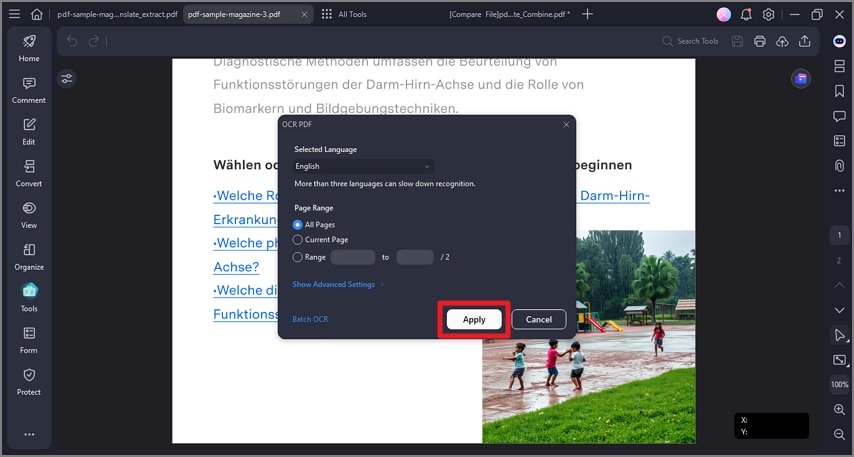
Passo 5Aplicar OCR
Se você só precisa de uma seção específica, pode escolher um intervalo de páginas. Caso contrário, clique em "Aplicar" para começar. Uma barra de progresso mostrará o processamento em tempo real da IA.
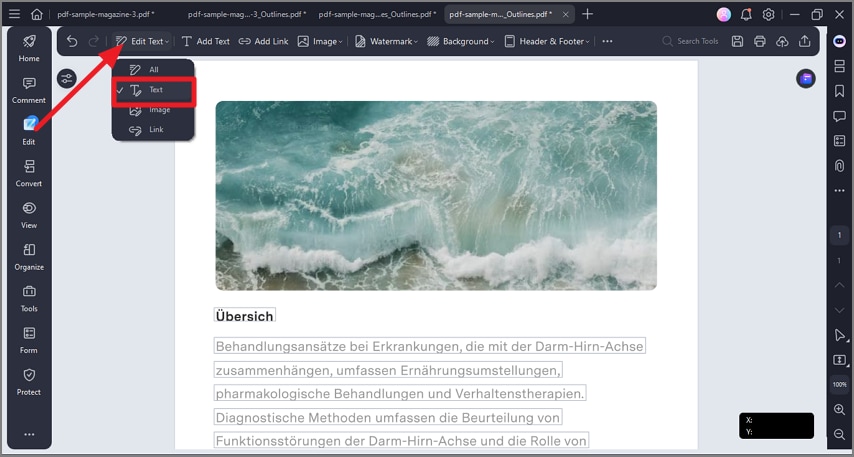
Passo 6Edite o documento
Após a conclusão, o documento é transformado. Agora você pode clicar no "Editar" botão e clique diretamente no texto. Você pode corrigir erros de digitação, alterar números ou atualizar parágrafos exatamente como faria em um processador de texto padrão, mantendo o layout perfeitamente intacto.
Vantagens de usar o PDFelement ao invés do LibreOffice para OCR
Embora o LibreOffice seja excepcional para criar novos documentos do zero, o PDFelement foi desenvolvido especialmente para gerenciar PDFs já existentes.
- Preservação Impecável do Layout: O PDFelement respeita a integridade visual do seu documento. As imagens permanecem em seus devidos lugares e as caixas de texto continuam alinhadas.
- Precisão Alimentada por IA: O mecanismo de IA lida com digitalizações inclinadas, textos com baixo contraste e fontes incomuns de forma significativamente melhor do que ferramentas on-line gratuitas.
- Segurança Offline: Todo o processamento OCR acontece localmente em sua máquina, garantindo que seus dados sensíveis nunca toquem um servidor público em nuvem.
- Kit de Ferramentas PDF Completo: Além da OCR, o PDFelement permite mesclar arquivos, assinar contratos digitalmente, redigir informações confidenciais e converter PDFs para os formatos Excel, Word ou PowerPoint com facilidade.
Comparação: Capacidades de OCR do LibreOffice vs. PDFelement
| Recurso/Métrica | LibreOffice (com soluções alternativas) | Wondershare PDFelement |
|---|---|---|
| OCR Nativo Integrado | Não (Requer ferramentas/ extensões externas) | Sim (Motor integrado alimentado por IA) |
| Preservação do Layout | Muito Ruim (Texto extraído cru) | Excelente (Mantém o layout exato) |
| Facilidade de Uso | Complexo (Exige alternar entre aplicativos) | Muito Fácil (Processamento com um clique) |
| Privacidade dos Dados | Baixa (Se usar ferramentas web gratuitas) | Alta (Processado localmente) |
| Idiomas Suportados | Varia conforme a ferramenta de terceiros | 20+ idiomas suportados nativamente |
| Melhor Aplicação | Extração de texto gratuita e casual | Edição profissional e precisa de PDF |
Avaliação G2: 4,5/5 |100% Seguro
Melhores práticas para resultados de OCR de alta qualidade
Independentemente de você usar uma extensão do LibreOffice ou uma ferramenta premium como o PDFelement, a qualidade do resultado OCR depende fortemente da qualidade do arquivo de entrada. Siga estas dicas para garantir os melhores resultados:
- Resolução Ideal: Certifique-se de que o scanner esteja configurado para pelo menos 300 DPI (Pontos Por Polegada). Qualquer valor menor pode resultar em texto borrado que o software terá dificuldade para ler.
- Iluminação e Contraste Adequados: Se estiver tirando uma foto do documento com o celular, assegure que não haja sombras sobre a página e que o texto contraste fortemente com o papel.
- Mantenha Reto: Textos inclinados ou tortos reduzem a precisão do reconhecimento. Embora ferramentas como o PDFelement autocorrijam a inclinação, fornecer uma digitalização reta gera resultados mais rápidos e precisos.
Conclusão
Encarar uma tarefa de OCR em PDF no LibreOffice exige entender o que o LibreOffice pode ou não pode fazer. Como o LibreOffice não possui um mecanismo OCR nativo, os usuários dependem de conversores online externos ou extensões complexas como LibreOCR para extrair texto. Embora esses métodos sejam gratuitos, muitas vezes resultam em perda de formatação, tempo desperdiçado e riscos potenciais de privacidade.
Para quem lida frequentemente com documentos digitalizados, investir em um editor de PDF dedicado como o Wondershare PDFelement é a escolha mais inteligente. Com OCR aprimorado por IA, interface intuitiva e a capacidade de preservar layouts originais, o PDFelement transforma a frustrante tarefa de digitação manual em um processo fluido com um clique. Escolha a ferramenta que melhor se adapta ao seu fluxo de trabalho, conforto técnico e necessidades de gestão de documentos.
Perguntas Frequentes
-
O LibreOffice pode fazer OCR em anotações manuscritas?
Não, o LibreOffice não pode fazer OCR de anotações manuscritas. Além disso, ferramentas OCR padrão normalmente não reconhecem bem a escrita à mão. Você vai precisar de um software especializado de Reconhecimento Inteligente de Caracteres (ICR) ou ferramentas de IA avançadas como o PDFelement para transcrever com precisão manuscritos, que depois podem ser exportados como texto e colados no LibreOffice. -
O OCR do LibreOffice é gratuito?
Como o LibreOffice em si não possui OCR nativo, o custo depende do método alternativo utilizado. Usar serviços online gratuitos de OCR ou instalar motores open-source como o Tesseract é grátis, mas exige tempo para correções manuais. Ferramentas dedicadas e de alta precisão geralmente requerem licença ou assinatura. -
Como instalo a extensão LibreOCR?
A instalação do LibreOCR geralmente envolve baixar o arquivo de extensão (.oxt) do repositório de extensões do LibreOffice, abrir o LibreOffice, navegar até o Gerenciador de Extensões e adicionar o arquivo. Porém, também é necessário instalar o Tesseract em seu sistema operacional e configurar os caminhos corretamente para que a extensão funcione. -
Por que meu texto OCR está cheio de erros ortográficos?
Isso geralmente ocorre quando a imagem de origem está em baixa qualidade (baixo DPI, borrada ou com baixo contraste) ou foi selecionado o idioma errado nas configurações do OCR. Certifique-se de que suas digitalizações estejam nítidas e utilize motores de OCR de alta qualidade como o PDFelement para minimizar erros de reconhecimento.